Research project: Estimating Maximum Magnitude Of Earthquakes on the Great Sumatran Fault
Currently Active:
Yes
When estimating hazards associated with earthquakes a key step in the process is understanding the structures that generate them. The Sumatran fault (also Great Sumatran fault, GSF) is a 1,800 km long strike slip fault running along the island of Sumatra. Strike slip faults are known to have a segmented character which has a direct impact on the size (small segments ~ small earthquake potential; large segments ~ large earthquake potential) and dynamics of earthquake ruptures. If segment length is known one can estimate the largest earthquakes the fault is likely to produce.
Project Overview
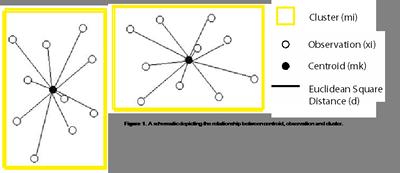
Figure 1
The K-Means Algorithm
A K-means algorithm divides data into clusters [Hartigan, 1975]. It identifies groups found in data that correspond to some ‘natural' phenomena. The algorithm forms clusters through an iterative process that aims to minimise the overall total sum of the distance between each cluster Centroid mk and their associated observations xi (figure 1).
Methodology
In this case clusters are representative of changing seismicity along a fault; assuming that the different seismicity's are directly associated with segments, the number of clusters defined by the algorithm will be the number of segments composing the fault. Since the number of clusters K for the data set is unknown it becomes necessary to use an a priori reasonable range of K. The problem this presents is identifying optimum K amongst the range of K investigated. The Krzanowski and Lai [1988] (KL) index is used to do this, for which an optimum K amongst the range of K will maximise the KL index (figure 2).
Results
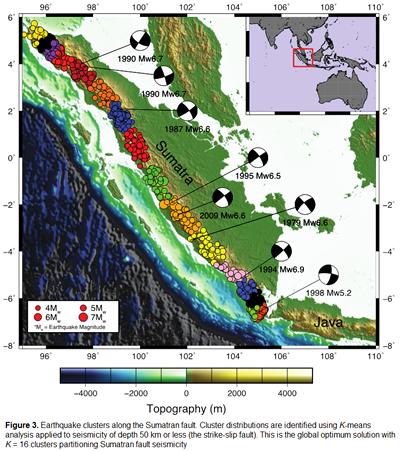
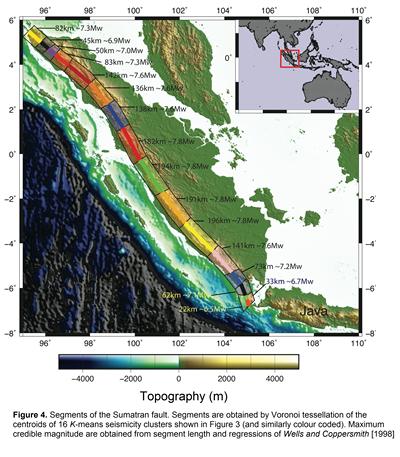
Figure 2 shows the respective KL index for when the fault is comprised of 2-25 clusters. The chosen model is the 16 cluster model with seismicity limited to 50km depth (figure 3). Through a tessellation algorithm and using regression equations put forward by Wells and Coppersmith [1998] the cluster model can be used to estimate segment length and maximum credible magnitude (Mcred )(figure 4).
Figure 3
Segment lengths are estimated in the range of 22-196 km and corresponding magnitudes for Mcred in the range 6.5-7.8Mw. These segment lengths span 45-182 km in the north and 22-196 km in the south, with magnitude ranges 6.9-7.8Mw and 6.5-7.8Mw respectively.
Figure 4
Conclusions
The Sumatran fault has 16 segments determined from a K-means cluster analysis
Segment sizes are estimated to be in the range 22-196 km for the Sumatran fault
Maximum magnitudes estimated along the Sumatran fault are 6.5-7.8Mw
Harrtigan, J.A. (1975), Clustering Algorithms, John Wiley and Sons, New York.
Krzanowski,W.J., and Y.T. Lai (1988), A criterion for determining the number of groups in a data set using sum-of-squares clustering, Biometrics 44, 23-34. Wells, D.L., and K.J. Coppersmith (1994), New empirical relationships among magnitude, rupture length, rupture width, and surface displacements, Bull. seis. Soc. Am., 84, 974-1002.