
Fig. 1: Hypertext Data Model.
Authors
Hugh Davis
The Multimedia Research Group
Dept. of Electronics and Computer Science
The University of Southampton
UK, SO 17 1BJ
email hcd@ecs.soton.ac.uk
Sigi Reich*
Dept. of Information Systems
University of Linz
A-4040 Linz, Austria
email sre@ifs.uni-linz.ac.at
Antoine Rizk
Euroclid, 12 av des Pres
78180 Montigny le Bretonneux, France
email Antoine.Rizk@inria.fr
A number of open hypermedia systems have been developed during the past years; some of them are still in their prototype stage, others are available as commercial products. Though open each of them has its own communication channels and requirements, its own data model and its own representation of hotspots. Yet there are many common features and interoperability seems to be a promising and challenging issue. In this contribution we address this issue of interoperability between open hypermedia systems, in particular between client applications and open hypermedia linkservices. We introduce a common data model, reflect on architectural assumptions, and finally present a proposal for an open hypermedia protocol. We describe the relationship to related technologies and also present scenarios that address both the need and the applicability for an open hypermedia protocol. The full definition of the proposed ASCII type protocol can be found in the Appendix.
Open hypertext systems (OHS) have been an active area of research for around ten years. There have been a number of OHS workshops at the annual ACM hypertext conferences as well as main conference sessions on OHS, and members of the community have held working groups between conferences. The community has now reached a level of maturity and stability such that it is possible to abstract the common features of the various systems, and to propose that we move towards one of the major goals of any open system: interoperability.
In order to introduce this topic, we will first define what we mean by the term "open" with reference to hypertext systems.
In the Open Systems community the term open is generally assumed to mean that there is some interface through which it is possible to communicate with some system or subsystem. A number of authors (Davis et al., 1992, Østerbye & Wiil, 1996) have attempted to define the term "open hypermedia". The open hypermedia community (Aßfalg, 1994, Wiil & Østerbye, 1994, Wiil, 1996, Wiil, 1997) have adopted the view that open hypermedia systems are not only those in which the components may be distributed across heterogeneous platforms, but also believe that such systems should provide hypermedia services to all applications on the desktop. Such systems should not be confined to simple models of hypertext, but should be extendible to work with new models, new data formats and new desktop applications. Users should not be confined to using passive browsers, but should be able to edit both content and structure (given appropriate permissions) and should be able to negotiate with linkservers about the sort of links to be provided.
The World Wide Web is an open system in that it provides a protocol (HTTP) through which a browser may communicate across the internet with a server. The use of this protocol makes it possible for third parties to produce their own browsers and servers. However, the World Wide Web has not generally been considered an open hypermedia system, since the Hypertext (as embodied by the Href's within html) is very simple, and is entirely embedded within the html rather than held separately.
On the other hand, although most of the so called "open" hypertext systems produced by the OHS community keep links separately and allow desktop applications to participate in the hypertext, they have all tended to use their own (proprietary) protocol for communication between the linkservice and the participating application. Although, in theory, any application that speaks the protocol may particpate, in practice any given linkserver is not "open" to co-operating with application programs (browser/editors) from other systems.
However, the premise of this paper is that there is now enough common agreement within the community to make it possible to define a protocol which could be adopted by the community, and indeed others, such as the WWW community who wish to expand the concept of hypertext within the web.
The obvious advantage of adopting such a protocol is that, just as has happened within the World Wide Web, it will be possible to build browser/editor programs just once and they will be able to communicate with a whole range of linkservers. Currently, open hypermedia systems tend to support only their private protocol, and as a result each system developer must also develop client side applications to talk in this protocol. Those who have worked with the web and with commercial hypertext systems will know that the cost and effort involved in producing a browser/editor is a large proportion of the effort in producing a hypertext system.
An application program which talks some standard protocol will be able to talk to any linkserver, on the internet for example, about hypertext objects. Initially this might be achieved by providing some shim program which would translate between the standard protocol and the linkserver's native protocol. This means that once an application has been developed for some client architecture, it will be able to work with all linkservices. Similarly, programs with macro languages could be adapted to talk OHP.
However, once the standard protocol was widely adopted it should lead to a new generation of linkservers, which would use the standard protocol as their native protocol. We envisage that the community could then use the protocol as the basis for tools for a new generation of distributed linkservers and client applications on the internet, in much the same way as HTTP defined the World Wide Web.
We have structured our paper in four major parts. The first part introduces the concept of linkservices. The second part attempts to define an all-inclusive data model for the entities involved in hypertext and open hypermedia systems, such as links, nodes and endpoints. The third part deals with the assumed architecture; note however, that we are not defining a reference architecture. In part four we present a number of scenarios that show how different open hypermedia systems can communicate. The fifth part introduces a proposal for a possible protocol. Part six reviews related technologies. We finish with a conclusion.
We have put a draft definition for an open hypermedia protocol in the Appendix. This appendix defines an asynchronous protocol using tagged ASCII text strings in order to achieve interoperability between clients and linkservices.
Open hypermedia systems are characterised by holding the hypertext stuctures (links etc.) separately from the actual document content. The structural link information is kept in a database (sometimes called a linkbase) and managed by a "linkserver" or "hyperbase".
Since some of our readers may be unfamilar with the sort of communications that happen between linkservers and their clients, we thought it might be useful at this point to give a high level description of a typical session.
Let us start by assuming that the linkservice has just received a message requiring it to follow a link to an anchor which is at a position some distance through a text document. There is no application which handles text documents currently running on the client. The chain of events might now proceed as follows.
The above description will serve as a background scenario to allow us to define a data model and to lead us to our proposed protocol.
The hypertext community has invested much time and effort in attempting to define hypermedia, and probably the most successful result is the Dexter model ( Grønbæk & Trigg, 1996, Halasz & Mayer, 1994). In this section we attempt to define the terminology and model that is assumed by the hypertext community.
This description attempts to be as inclusive as possible in the sense that the model is capable of representing the link models assumed by most existing hypertext systems. However, inevitably some systems have features that will not easily fit within this description, e.g. transclusions in Xanadu (Pam, 1997) or spatial hypertext systems (Marshall, 1994). The complete data model will appear more complex than that of many existing systems, but the reader should understand that it will not always be necessary to expose the user to this complexity.
Figure 1 basic entities of the hypertext data model, and their relationships.
Fig. 1: Hypertext Data Model.
The model of hypertext assumed in this paper is one in which servers hold links, endpoints, references and nodes. Each of these objects have unique identifiers within the system. Servers which manage these objects are known as linkservers.
A link is an object which represents a connection between zero or many endpoints. A link may (or may not) have a type (e.g. "defines"). In many systems traversing a link may cause some process to run as well as or instead of causing the focus to move to some point at the end of the link. For example the link shown in figure 2 has three endpoints.
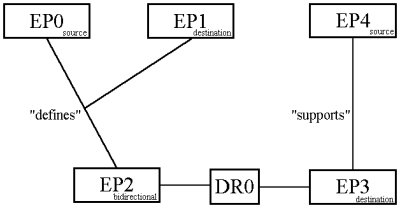
Fig. 2: Example of Data Model.
An endpoint is an object which holds the attributes of the end of a link. Typically an endpoint will hold a traversable direction which might be source, destination or bi-directional. For example, in figure 2, the link may be traversed from EP0 to EP1 and EP2, and it may be traversed from EP2 to EP1, but it will not be possible to traverse this link from EP1.
A dataRef defines the node and the point within that node at which the viewer application should indicate some kind of persistent selection which will be a hypertext "hotspot". We have deliberately avoided the use of the words "anchor" and "button" as these terms have been somewhat overloaded in the past. A dataRef therefore consists of a nodeSpec and a LOCSPEC. A dataRef may be associated with zero or more endpoints. For example, a user may make a number of datRefs before associating any of them with any endpoint of any link. Also, one datRef might refer to more than one endpoint, and these endpoints might belong to different links. For example datRef DR0 in figure 2 is associated with both EP2 and EP3.
A nodeSpec will resolve to one or more node identifiers (nodeID's) which will each uniquely identify one node.
A node is a wrapper object which holds the meta-data about some content data including the information about where to find the file or files which make up that content data. This content data is defined by a CONTENTSPEC.
A location specifier (LOCSPEC) holds the information that defines the position at which the persistent selection should be dispalyed as well as any presentation information.
A presentation specifier (or PSPEC) may be associated with any hypertext object and defines how that object should be displayed at run time.
Sometimes a link or dataRef may have an associated script which is executed when the link or reference is used.
In the above definitions, the terms CONTENTSPEC, LOCSPEC and PSPEC have all been shown in uppercase. This is to signify that their definition is outside the scope of the data model and that they are therefore opaque, whereas all terms shown in lowercase are fully defined within the data model. However, within the scope of the suggested protocol shown in the Appendices we made some proposals for possible realisations of these opaque objects.
If a linkservice stores the content data as well as the hypertext objects, then it may be referred to as a hyperbase, since it is a database storing the entire set of objects involved in the hypertext.
A linkservice is expected to provide a core set of linkservices which involve the creation, retrieval and use of links, endpoints, dataRefs, nodes, scripts and presentations. It will also be expected to provide some level of document management, for example, informing the client the name of the file it must load and display in order to complete a link traversal.
Many linkservices provide extra services, which assist the user in information retrieval and navigation.
Addressing interoperability not only requires some common understanding of the data model; also the underlying architecture should be investigated and agreed upon. This is because the data model usually makes assumptions about the architecture and because functionality and behavior are to a large extent based on the architecture. Therefore we will discuss general assumptions about the underlying architecture of open hypermedia systems. We will try to be as general as possible in doing so but we will not attempt to define a reference architecture. There is already some promising work in this area (Goose et al., 1997, Grønbæk & Wiil, 1997, Wiil & Whitehead, 1997) and we will only describe what we think is the minimum necessary to allow an implementation of the above data model.
In general, open hypermedia systems tend to implement a linkservice layer which provides the storage and access mechanism for links, endpoints and dataRefs. The Dexter reference model (Halasz & Mayer, 1994) refers to this as the storage layer. Some systems call this layer a hyperbase; such systems usually store not only the links, but also the nodes (i.e. the contents) in this layer. The distinctions between the different types of system are ill defined, and not the subject of this paper. The thing that all such systems have in common is that the application layer (or runtime layer) is physically separate from the storage layer, and that there is some system communication between the two, which allows the applications (editors, viewers) to send and receive messages and query the linkservice concerning hypertext services. Figure 3 depicts this relationship.
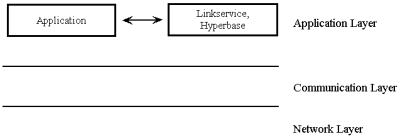
Fig. 3: Components and Layers.
An application layer protocol, such as the hypertext protocol we are suggesting should not be concerned with the mechanics of how a connection is achieved between a particular application and a particular linkservice, or how a message is routed between the components. Consequently we can imagine implementations of the hypertext protocol using ASCII text messages over TCP/IP, or alternatively we can imagine implementations using IIOP and CORBA interfaces. The next section discusses some of these options, but in the Appendices we present a possible protocol using ASCII text messages.
However, there is a problem that impedes the simplicity of the model which has the application program communicating directly with the link service. In practice all those who have implemented linkservices have identified the need for some component on the client side which is present throughout the hypertext session. (Goose et al., 1997) called it the "Runtime", (Wiil and Leggett, 1996) call it the "Tool Integrator" and in the original version of this protocol (Davis et al., 1996) it was called the "Communication Protocol Shim". However, we prefer, now, to call it the CSF. (This acronym actually stands for Client Side Foo, which, following Ted Nelson's advice not to use overloaded terms, we adopted in order to prevent any further argument about the name). Figure 4 gives a graphical representation.
The responsibilities of the CSF will always include starting an application (with its data) when required to by the linkservice (e.g. as the result of traversing a link to a document which must be handled by some application which is not currently running). This function is necessary as in heterogeneous systems it is not always possible for a server application to start a client on a remote machine.
There are many other tasks that might need to be carried out on the client side, which include such tasks as
For the above reasons we believe that it is necessary that all communication between client side applications and linkservers are routed through the CSF. For example, this make it possible for the CSF to intercept and handle all requests to produce content.
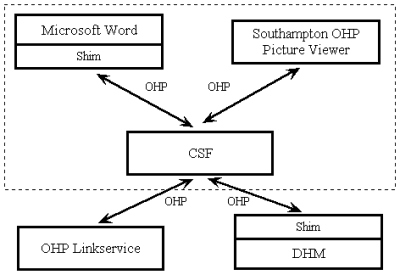
Fig. 4: Usage of Shims for Interoperability.
Figure 4 gives an example of the kind of architecture was are assuming, and assumes an open hypertext protocol such as OHP (defined in the Appendix). In this figure there are two client side applications. One is Word, which has been adapted as a OHP aware viewer using its macro language, and one is a special purpose picture viewer which was written to work with OHP. Both these communicate with the linkservers via the CSF using the OHP protocol. One of the servers is a native OHP server, whereas the other might be a DHM (DeVise Hypermedia) server, and a shim has been inserted in order to convert the OHP protocol to the DHM native protocol.
Besides the components application program, linkservice and CSF there is a fourth component, the Document Management System (DMS). We are convinced that an additional protocol - a document management protocol (DMP) - should allow standardized communication to document management systems. The Open Document Management API (Open Document Management, 1997) could serve as a good example and some of the concepts in the hypertext data model, e.g. the definition of a NodeId as a unique document identifier, follow this proposal.
In this section we consider a number of existing scenarios that current existing systems handle. We also consider some of the work the OHS working group has been doing on scenarios (see http://www.csdl.tamu.edu/ohs/scenarios/). The purpose of considering scenarios is to understand the requirements of open hypermedia systems and to use these requoirements as the basis of the design of an open hypermedia protocol.
A Microcosm semi-aware viewer might be a program such as Word for Windows, which has been adapted, usually by the use of application specific macros, to allow the user to make selections and request actions. For the purpose of this example we will assume that we are not going to attempt to enable the application to handle persistent selections: in Microcosm terms this viewer will not handle buttons or specific links, but will allow the user to create local and generic links, and will allow the user to follow such links and to request other services such as computed links.
The linkservice, on receiving this request would note that no LocSpec information, other than the content, had been provided, and would thus start up the link making dialogue with options to create local or generic links.
The above scenario demonstrates that the protocol must not be too "heavy" in its requirements on a client. A simple client must be allowed to provide only that information which it can. Furthermore, we see from the above description that the user interface to a client system need not reflect exactly the assumed data model. Microcosm has no concept of multi headed links or endpoints. A link is simply a directional connection between two dataRefs. It should be possible to build a user interface that behaves like Microcosm, in a client that automatically maps the simpler data structure onto the more complex data structure assumed by the standard protocol.
Now let us consider the case of Word for Windows adapted as a fully aware Microcosm viewer. In this example perhaps the user follows a link to a node that is a Word for Windows document held on the network file system.
Before leaving Microcosm, it is worth making two particular points.
Many of the classic Dexter systems expect that the application will own the anchor table (endpoint table in our terminology). Such systems might store this table with the data, or might arrange to store the table outside the data in a separate but associated file. When a new anchor is created, its identifier is allocated by the viewer application and is unique within that context. The links that are stored within the linkservice have ends which consist of a (Document Name, AnchorID) pair.
Storage and delivery of the anchor table for each document have to be handled by the CSF. Thus when a request for anchors is received by the CSF, it will retrieve the correct file (which it will identify from the request). The linkservice itself will never see this message. The viewer will communicate to the linkservice about anchors in terms of the anchorID and perhaps the LocSpec, and the shim will convert this information into an anchorID and a document's name.
Since such linkservices do not normally provide a service for allocating anchor identifiers, the protocol shim will need to provide the service instead. When the viewer sends a service request for a new anchor, the OHP shim will consult the appropriate anchor table and allocate the next available anchorID, which it will pass back to the viewer.
So-called hyperbase systems are characterised by the fact that they are mostly build on top of databases and that they not only store the link information but also the document content. Thus most hyperbase systems differ from the descriptions given so far in two respects:
Where a viewer is being specially built for a format that will only be used hypertext systems it is likely that the developer will specify a data format in such a way that the persistent selections may be held as mark-up within the data. Such a format is htf used by Hyper-G (Andrews et al., 1995). In such cases the endpoint will be encoded into the mark-up and passed to and from the linkservice to identify the ends of links. These endpointID's might be unique to the document or to the linkservice as a whole. It is important to realise, however, that not all the endpoints held in the document will necessarily be currently valid. In many systems separate Webs of links may be installed, and the endpoints that will be valid will depend on the choice of Web.
Therefore, such a viewer must still send a request for the endpoint table to the linkservice: only those endpoints which the linkservice returns should be offered to the user.
Achieving interoperability by a simple ASCII protocol mechanism based on TCP/IP is one possible approach. In fact, we follow this approach with the proposal of an asynchronous protocol called the open hypermedia protocol (OHP). This definition can be found in Appendix A.
We see the main advantage of this approach in its simplicity. It should be easy to implement without putting too much onus on the client application; the protocol could even be tunneled in HTTP allowing Web browsers to access linkservices.
Having defined an abstract yet common data model for open hypermedia linkservices and having general assumptions of the underlying architecture in mind we are now able to think about possible implementations. In this section we will thus address the issue of related and/or relevant technologies.
A question that has often been posed to the open hypermedia research community is, why do we not use existing standards such as OLE and CORBA? The usual answer has been that these standards do not provide the correct services, and anyway they are by no means standard across architectures, or are not (yet) in common use. It is worthwhile, however to consider at this point how existing and emerging standards might be of use for achieving the goal of interoperability.
The prevailing problems, when it comes to hypertext enabling an application are:
In the remainder of this section we investigate HyTime, ActiveX, ODMA, WebDAV, PEP, CORBA, and Java Beans.
Hypermedia/Time-based Structuring Language (HyTime, ISO, 1992) is a standard being developed for managing time-dependent structured information in a platform independent way. It uses the Standard Generalized Markup Language (SGML) for its representation.
Operas have often served as general examples demonstrating the capabilities of HyTime. The main point is: how could you describe the scenes, the music, the actors, etc. of an opera in a platform independent way in order to allow the performing ot the same opera at different places, e.g. in Milano or New York or wherever you like?
This idea can well be applied to open hypermedia linkservices: how could one describe link information in a platform independent way in order to have it presented to the user by different tools with their specific presentation needs? Consequently, with respect to interoperability in open hypermedia linkservices HyTime's role can be characterised by the following facts:
Microsoft focuses with ActiveX (McKeown, 1996) mainly on the navigational aspects of hyperlinking, i.e., point-and-click hyperlink navigation within Microsoft office applications. Microsoft uses a tuple as a referencing mechanism. A tuple consists of a target and a location. The navigation to the location is done by binding to the target and then asking it to navigate to the location.
Hyperlink container, frame and site are additional concepts of ActiveX/OLE. A container consists of at least one hyperlink, a frame can manage containers and resides on the Internet (e.g. any running Microsoft Internet Explorer application). A site is within a document and would be called an anchor in Dexter (although embedded within the document).
ActiveX Controls are comparable to Java applets; however, they are cross-platform and not multi-platform so they have to be compiled for each platform they are used. ActiveX Controls can be used from within a variety of programming languages. Built on OLE 2.0, ActiveX controls can be used in Web browsers (currently only Explorer 3.0 and Netscape with the Ncompass plug-in), desktop applications, and development tools.
From an interoperability's point of view ActiveX suffers some major disadvantages:
ODMA (Open Document Management API, 1997) is an application programming interface being published by the ODMA consortium in order to provide a standard for clients integrating with a document management system.
ODMA is a standardised, high-level interface between desktop applications and document management systems. Its main goals are
Interestingly, ODMA defines a "connection manager" which is a small software module that sits between applications using ODMA. This idea of the connection manager is similar to the approach of assuming a client side foo (CSF).
With respect to interoperability in open hypermedia linkservices ODMA could very well play a role as a standardised API for accessing and managing documents. The proposal for a common data model described above uses some abstractions for document management that follow the general idea of ODMA. By that, a later integration of these two approaches should be very straightforward.
World Wide Web Distributed Authoring and Versioning (WebDAV, IETF WebDAV, 1997) is an Internet Engineering Task Force working group's effort to support authoring and versioning over the Internet, in particular the World-Wide Web. The main goal of the working group is to propose standard extensions for HTTP to address issues such as
The implementation of the concepts is proposed to be done by use of tools such as Microsoft Frontpage, America Online PrimeHost AOLpress and AOLserver, Netscape Navigator Gold or Amaya.
From an OHP linkservices point of view the WebDAV initiative mainly focuses on allowing collaboration over standard HTTP browsers. It proposes extensions to HTTP in order to do so; this is different to the approach presented in this paper in that also existing viewers and systems should be adaptable to a standard link protocol.
The World-Wide Web Consortium proposes a standardised way to extend the HyperText Transfer Protocol. This extension is called Protocol Extension Protocol (PEP, Nielsen, 1997).
According to the authors, PEP should be used for applications that require more facilities than the standard version of HTTP provides, from distributed authoring, collaboration and printing, to various remote procedure call mechanisms.
PEP is intended to work as follows:
From an open hypermedia systems point of view PEP could be used in the communications layer which is represented by the CSF component. PEP could be seen as a possible way of implementing standardized open hypermedia services using HTTP as a protocol; additionally required semantics would be expressed conforming to PEP.
The Common Object Request Broker Architecture (CORBA, Object Management Group (OMG)) is a well known and widely accepted standard for middleware. By supporting the Internet Inter-ORB Protocol (IIOP) so-called ORBs can manipulate distributed objects transparently using CORBA services. CORBA services are collections of basic functionalities packaged with IDL (Interface Definition Language) interfaces. Standards for sixteen different services are published; most relevant from the perspective of open hypermedia linkservices is probably the Relationship Service.
The Relationship Service Specification (OMG, 1994) is a CORBA service that allows entities and relationships to be explicitely represented. It supports relationships along the dimensions type, cardinality, degree and role. Relationships as provided by the relationship service differ from 'ordinary' object references in that
Although promising the relationship service might not be sufficient for implementing open hypermedia linkservices using CORBA. However, this is not a major restriction as a dedicated interface could be specified (using IDL). Thus, from the perspective of interoperability CORBA might well be an architecture for implementating the proposed data model and behaviour of its components.
The goal of JavaBeans (Hamilton, 1997) is to define a component model for Java. Main issues addressed include portability, uniform API and simplicity in the API.
We see JavaBeans as an interesting and potentially promising basic technology that would allow the implementation of a platform independent document model. Additonally, by supporting CORBA services JavaBeans well fulfill the criterion of openness and thus could be used to ensure interoperability.
Yet, from an open hypermedia linkservices point of view there are two arguments that do not advocate the usage of JavaBeans:
Following initial consultation within the OHS community, in this contribution we have proposed a protocol for open hypermedia systems that is based on a common data model. It will help us in achieving the aim of interoperability.
Besides abstracting common features of OHS we have specified the assumptions made to the underlying architecture in order to develop a common data model. We also have described a number of scenarios that show both the need and the applicability for an open hypermedia protocol.
We have described the relationship to related technologies that could be used for implementing this protocol.
We now feel the proposed protocol is ready for publication and discussion within a wider community. In particular we believe that the internet community should now consider this proposal.
We believe that the next stage in developing this protocol should involve
In attempting to solve the above problems, we believe that a number of further issues will become apparent and will need further attention. Those that we are currently aware of are:
The editors would like to thank the OHS community, all of whom have contributed to this paper, but special thanks are due to Pete Nürnberg from Texas A&M University, Ken Anderson and Richard Taylor from University of California Irvine, Randy Trigg from Xerox Parc, Palo Alto, Uffe Kock Wiil from the University of Aarhus, Denmark, and Ian Heath, Mark Weal, Andy Lewis, Stuart Goose, David Millard and many others from the University of Southampton, UK, who contributed significantly to this article.
We would also like to thank the referees that provided excellent feedback on a previous version of this document.
This Appendix defines the protocol as well as a proposal for location specifications, presentation specifications and document identifier specifications.
OHP is a peer to peer asynchronous protocol. Messages may be sent by either the linkservice or by the application program. If a reply is expected, it is up to the receiving component to initiate a new message. There are thus two main classes of messages to be considered; those sent by the application program and those sent by the linkservice.
In order to allow readers to 'play' with OHP and to better visualise the communication process we have developed a small Java applet that should help in understanding OHP.
The simple applet is based on the assumptions we have made about the components being involved in an OHP scenario. On the OHP level we thus only have two components, application program and linkservice, that talk OHP to each other. The communication layer is not shown in the applet.
In order to play with OHP select a scenario and walk through it by pressing 'start'.
Fig. 5: Java Applet allowing to play with OHP.
For actually defining the mechanics of OHP we will follow a Backus-Naur Form (EBNF) as is for instance done in Internet drafts. We use the following constructs:
- name = definition
- "literal"
- {elem1 | elem2}
- {elem}*
- {elem}+
- [elem]
- <elem>
- ELEM
Additionally we assume the following rules (the US-ASCII coded character set is defined by ANSI X3.4-1986):
- CHAR =
- UPALPHA =
- LOALPHA =
- ALPHA = UPALPHA | LOALPHA
- DIGIT =
- CTL =
- CR =
- LF =
- SP =
OHP messages will consist of text strings (CHAR). In the following sections the messages are shown formatted on multiple lines for ease of presentation. However, the messages themselves will be one continuous stream of ASCII text, unbroken by line feeds (LF). The messages consist of Tags, which are proceeded by a backslash ('\') and succeeded by a white space (SP). The characters that follow, up to the next tag or the end of the message are the tag contents. A tag content may be empty.
The tags that should occur in each message are explained in the protocol definition. They may be presented in any order. The protocol is designed such that if tags are missing, the system will attempt to work with the remaining information, and if extra undefined tags are present, systems that do not understand these tags will simply ignore them. If a backslash ('\') occurs within the tag content, then it should be quoted by preceding it with a further backslash.
We can now begin to define the protocol.
As opposed to the previous draft of OHP (Davis et al., 1996), which define a channel as an identifier for messages, we have defined a dedicated message header (see Thread "Channels in OHP" of OHS discussion list). As already mentioned above, OHP abstracts from the communication layer so the header does not include any host or port or other communication specific information.
Every message will have a message header. A message header will contain information about the transaction that both sides of the communication channel may from time to time need to examine. It is not immediately clear that all of this information is essential, but there is a general consensus that parts of this information will, at times, be necessary.
MessageHeader = MessageID ReturnMID VersionID SessionId UserID. MessageID = "\MID " <a unique identifier for the particular message>
Probably this will be realised by a time stamp.
ReturnMId = "\RMID " <the ID of the message this message is a reply to>
The RMID allows applications and linkservices to keep track of sent and received messages and by that keep state. This field can be left empty in case a message is sent that is not a reply to a previous message.
VersionId = "\VID " <current version of the protocol>
E.g. "2.1.Southampton" would indicate version 2.1 of the OHP protocol with Southampton extensions. The X.X part is essential, and the remainder can be ignored.
SessionId = "\SID " <a system dependant string which uniquely identifies
some "transaction" or "session">
We have not yet defined what a session is and we envisage that this will become significant when we attempt to deal with collaboration issues.
UserID = "\UID " <a system dependant string uniquely identifying the user>
The following table gives an overview of the basic messages that form the OHP protocol. The very left column defines the basic entities we have identified, i.e. link, endpoint, dataref, node, script, presentation specification (PSPEC) and services; the top line, i.e. the columns' labels, define the basic functions that can be processed on these entities. The functions are create, get, update, delete, add and remove item. Note that add and remove item are list specific functions. Lists are introduced as a means to allow aggregation of entities. An endpoint table for example would be dealt with in OHP as a list of endpoints.
|
|
Create |
Get |
Update |
Delete |
Execute |
Notification |
|
Endpoint |
X |
X |
X |
X |
X |
|
|
DataRef |
X |
X |
X |
X |
|
|
|
Link |
X |
X |
X |
X |
|
|
|
Node |
X |
X |
X |
X |
|
ClosingNode |
|
Script |
X |
X |
X |
X |
X |
|
|
PSpec |
X |
X |
X |
X |
|
|
|
Services |
|
|
|
|
X |
|
Tab.1: OHP Message Table
The following messages may be sent by the linkservice:
The Error message might be sent by any component being involved in an OHP session.
We will now present the messages in detail and also give examples or additional comments where necessary to understand the semantics of the protocol.
Note that some of the messages might be rarely used, some even never. However, for reasons of consistency and symmetry of the protocol we defined and kept them as part of the standard.
When a new endpoint has been created, the application program will send the following message to the linkservice. Generally an endpoint will need a dataRef, a PSpec and Service tags may well be defaults (e.g. blue and FollowLink respectively). Note, that not only an application program but also processes or scripts can create endpoints by sending this message.
MESSHEADER
"\Subject CreateEndpoint"
"\DataRefId " <DataRefId>
"\Direction " "Source" | "Destination" | "Bidirectional"
"\Service " <Service>
"\PSpecId " <PSpecId>
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
This message allows the application program to ask the linkservice for the current details of the endpoint identified.
MESSHEADER "\Subject GetEndpoint" "\EndpointId " <EndpointId>
Both messages, CreateEndpoint and GetEndpoint should be answered by the link service with an EndpointDef message.
Updates an endpoint's attributes given its ID.
MESSHEADER
"\Subject UpdateEndpoint"
"\EndpointId " <EndpointId>
"\DataRefId " <DataRefId>
"\Direction " "Source" | "Destination" | "Bidirectional"
"\Service " <Service>
"\PSpecId " <PSpecId>
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
Deletes an endpoint given its ID.
MESSHEADER "\Subject DeleteEndpoint" "\EndpointId " <EndpointId>
The application program, while running, is expected to maintain the list of endpoints. It may obtain this list, for a given node, by sending the following message.
MESSHEADER "\Subject GetEndpointList" "\NodeId " <NodeId>
The linkservice will reply by sending a "EndpointListDef" message.
When an anchor is activated (e.g. clicked ) the following message will be sent to the linkservice to request that whatever action is associated with that anchor (e.g. follow link) will be performed by the linkservice.
MESSHEADER "\Subject ExecuteEndpoint" "\EndpointId " <EndpointId>
Sent by the linkservice on request from an application program (CreateEndpoint or GetEndpoint), or possibly the linkservice might send this autonomously in the case where a new endpoint has been made by a user in a different session. The tag attributes is a list of attribute name and value pairs that contain all the attributes the linkservice knows about this object.
MESSHEADER
"\Subject EndpointDef"
"\EndpointId " <EndpointId>
"\DataRefId " <DataRefId>
"\Direction " "Source" | "Destination" | "Bidirectional"
"\Service " <Service>
"\PSpecId " <PSpecId>
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
Sent by the linkservice on request from an application program (Endpoint)
MESSHEADER
"\Subject EndpointListDef"
{"\Endpoints "
"\EndpointId " <EndpointId>
"\DataRefId " <DataRefId>
"\Direction " "Source" | "Destination" | "Bidirectional"
"\Service " <Service>
"\PSpecId " <PSpecId>
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
"\EndEndpoints "}*
The linkservice might request from the application program to display an endpoint ("hotspot") for example, as the end of a link that has been followed.
MESSHEADER "\Subject DisplayEndpoint" "\EndpointId " <EndpointId> "\PSpecId " <PSpecId>
DataRefs encapsulate attributes for location specification and the node itself. Some systems will require dataRefs to be created automatically when an endpoint is created; others with more complex user interfaces might allow users to create dataRefs and connect them to endpoints. Note that not only users but also system processes (including scripts) might create dataRefs.
MESSHEADER
"\Subject CreateDataRef"
"\NodeId " <NodeId>
"\LocSpec " LOCSPEC
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
This message allows the application program to ask the linkservice for the current details of the dataRefs identified.
MESSHEADER "\Subject GetDataRef" "\DataRefId " <DataRefId>
Both messages, Create DataRef and Get DataRef should be answered by the link service with an DataRefDef message.
Updates a dataRef's attributes given its ID.
MESSHEADER
"\Subject UpdateDataRef"
"\DataRefId " <DataRefId>
"\NodeId " <NodeId>
"\LocSpec " LOCSPEC
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
Deletes a dataRef given its ID.
MESSHEADER "\Subject DeleteDataRef" "\DataRefId " <DataRefId>
Sent by the linkservice on request from an application program (CreateDatRef or GetDataRef), or possibly the linkservice might send this autonomously in the case where a new endpoint has been made by a user in a different session. The tag attributes is a list of attribute name and value pairs that contain all the attributes the linkservice knows about this object.
MESSHEADER
"\Subject DataRefDef"
"\DataRefId " <DataRefId>
"\NodeId " <NodeId>
"\LocSpec " LOCSPEC
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
The next set of messages is concerned with the manipulation of links. In practice most application programs used for viewing data will not handle links, but only endpoints. This set of messages is provided partly in order to provide a symmetric set of messages handling all objects within the link service. However, we can envisage the case where a developer may wish to produce client side tools for the creation, manipulation and editing of links. From the point of view of the linkservice, it is unimportant whether the messages come from an application program or a link editor, and OHP should provide such messages.
MESSHEADER
"\Subject CreateLink"
"\Endpoints " {"\EndpointId " <EndpointId>}+ "\EndEndpoints "
"\Description " <Description>
"\Type " <Type>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Gets the attributes of a link given its ID. Both messages, CreateLink and GetLink should be answered by the linkservice with a LinkDef message.
MESSHEADER "\Subject GetLink" "\LinkId " <LinkId>
Updates a link's attributes given its ID.
MESSHEADER
"\Subject UpdateLink"
"\LinkId " <LinkId>
"\Endpoints " {"\EndpointId " <EndpointId>}+ "\EndEndpoints "
"\Description " <Description>
"\Type " <Type>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes a link given its ID.
MESSHEADER "\Subject DeleteLink" "\LinkId " <AnchorId>
An application program may be interested in manipulating the list of all links. Note that future versions might include a context tag or a query tag in order to allow the client to specify which list of links to get. At present it will deliver all links in the linkservice.
MESSHEADER "\Subject GetLinkList"
The linkservice will reply by sending a "LinkListDef" message.
Sent by the linkservice on request from an application program (CreateLink and GetLink).
MESSHEADER
"\Subject LinkDef"
"\LinkId " <LinkId>
"\Endpoints " {"\EndpointId " <EndpointId>}+ "\EndEndpoints "
"\Description " <Description>
"\Type " <Type>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Sent by the linkservice on request from an application program (GetLinkList).
MESSHEADER
"\Subject LinkListDef"
{"\Links "
"\LinkId " <LinkId>
"\Endpoints " {"\EndpointId " <EndpointId>}+ "\EndEndpoints "
"\Description " <Description>
"\Type " <Type>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
"\EndLinks "}*
Again, as with links, we do not believe that the typical application program will be interested in manipulating nodes, but since nodes are handled by many linkservices, it seems appropriate to provide an interface to these objects so that developers may produce client side tools to manipulate them, such as browsers. The reader is reminded that in this context a node is a wrapper object that contains the meta-data about a document, rather than the document itself.
OHP is not a protocol for dealing with the actual storage and retrieval of documents. We assume that at some stage a protocol will be created for doing this (HTTP is actually one such protocol, if limited in some aspects; the Open Document Management API proposes another see Open Document Management API, 1997). Yet, actually managing content as is represented by documents is what will make OHP a useable protocol. For the moment we will therefore abstract in the definition of the protocol by using an opaque string representing a document. ("CONTENTSPEC"). However, we also will make some assumptions which components are going to deal with this string in what way, and these are proposed in Appendix C Content Specification.
The following message will create a new node in the linkservice. This message is perhaps the one message related to nodes that might be used by an application program, in the case where a client side program had just loaded or created a new document and wished to register it with the link service.
MESSHEADER
"\Subject CreateNode"
"\NodeName " <A title that the application may choose to display>
"\MimeType " <MimeType>
"\PreferredApp " <The name of the application which we would prefer to use
with this data>
"\ContentSpec " CONTENTSPEC
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Gets a node's attributes given its ID.
MESSHEADER "\Subject GetNode" "\NodeId " <NodeId>
Both messages, CreateNode and GetNode should be answered by the link service with a NodeDef message.
Updates a node's attributes given its ID.
MESSHEADER
"\Subject UpdateNode"
"\NodeId " <NodeId>
"\NodeName " <A title that the application may choose to display>
"\MimeType " <MimeType>
"\PreferredApp " <The name of the application which we would prefer to use
with this data>
"\ContentSpec " CONTENTSPEC
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes a node given its ID.
MESSHEADER "\Subject DeleteNode" "\NodeId " <NodeId>
An application program may be interested in manipulating the list of all nodes. Note that future versions of OHP might include a context tag or a query tag in order to allow the client to specify which list of nodes to get. At present it will deliver all nodes in the linkservice.
MESSHEADER "\Subject GetNodeList"
The linkservice will reply by sending a "NodeListDef" message.
Sent by the linkservice on request from an application program.
MESSHEADER
"\Subject NodeDef"
"\NodeId " <NodeId>
"\NodeName " <A title that the application may choose to display>
"\MimeType " <MimeType>
"\PreferredApp " <The name of the application which we would prefer to use
with this data>
"\ContentSpec " CONTENTSPEC
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Sent by the linkservice on request from an application program (GetNodeList).
MESSHEADER
"\Subject NodeListDef"
{"\Nodes "
"\NodeId " <NodeId>
"\NodeName " <A title that the application may choose to display>
"\MimeType " <MimeType>
"\PreferredApp " <name of the application which we would prefer to use
with this data>
"\ContentSpec " CONTENTSPEC
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
"\EndNodes "}*
Scripts play an important part in some hypermedia systems (e.g. Hypercard and Multicard), and are hardly used in others. Scripts may be classified into two types:
This message is used to create a new script ID. Required parameters are the name of the script language as well as the actual script.
MESSHEADER
"\Subject CreateScript"
"\Language " <name of the script language, e.g. JavaScript, etc.>
"\Data " <the actual script>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Gets the attributes of a script given its ID. Both messages, CreateScript and GetScript should be answered by the linkservice with a ScriptDef message.
MESSHEADER "\Subject GetScript" "\ScriptId " <ScriptId>
Updates a script's attributes given its ID.
MESSHEADER
"\Subject UpdateScript"
"\ScriptId " <ScriptId>
"\Language " <name of the script language, e.g. JavaScript, etc.>
"\Data " <the actual script>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes a script given its ID.
MESSHEADER "\Subject DeleteScript" "\ScriptId " <ScriptId>
A client may send this message to the server, in which case the server will execute the given script, or a linkserver may send this message to a client, in which case, if the client does not currently have the script identified, it will need to send a GetScript message back, in order to execute the script on the client.
MESSHEADER "\Subject ExecuteScript" "\ScriptId " <ScriptId>
Sent by the linkservice on request from an application program.
MESSHEADER
"\Subject ScriptDef"
"\ScriptId " <ScriptId>
"\Language " <name of the script language, e.g. JavaScript, etc.>
"\Data " <the actual script>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Alternative presentation of anchors is an important feature in some systems. OHP allows users to specify different presentations. From the point of view of OHP and linkservers, presentation specifiers (PSpecs) are opaque strings, which are interpreted by the application program. However, in order to allow for interoperability or application programs, and in order to allow server end scripts to change the presentation in a client, it is useful to attempt some standardisation of the content of the PSpec. This is discussed in Appendix B Presentation Specification.
Used to create a presentation specification.
MESSHEADER "\Subject CreatePSpec" "\PSpec " PSPEC
Returns a presentation specification's attributes given its ID. Both messages, CreatePSpec and GetPSpec should be answered by the linkservice with a PSpecDef message. This ID then can be used as parameter in further message calls.
MESSHEADER "\Subject GetPSpec" "\PSpecId " <PSpecId>
Updates a presentation specifications attributes given its ID.
MESSHEADER "\Subject UpdatePSpec" "\PSpecId " <PSpecId> "\PSpec " PSPEC
Deletes a presentation specification given its ID.
MESSHEADER "\Subject DeletePSpec" "\PSpecId " <PSpecId>
Sent by the linkservice on request from an application program.
MESSHEADER "\Subject PSpecDef" "\PSpecId " <PSpecId> "\PSpec " PSPEC
The "GetServices" message is to be sent from application program to link service in order to know which additional services are available, above the standard set which manipulate anchors, links, nodes and presentations. The linkservice should answer this request with a "ServicesDef" message. Services are defined by a description and a service name.
MESSHEADER "\Subject GetServices"
The ExecuteService message is a very general message that can be used by the application program to request a linkservice to do one of its services. The available services can be retrieved by the GetServices message.
MESSHEADER
"\Subject ExecuteService"
"\Service " <name of the service>
"\EndpointId " <EndpointId>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Sent by the linkservice on request from an application program (GetServices).
MESSHEADER
"\Subject ServicesDef"
{"\Services "
"\Service " <name of the service>
"\Description " <a string which may be used to describe the service to
a user>
"\EndServices " }*
The minimum reply should include the service named "FollowLink", which all linkservers must handle. All other services are server dependant.
This message is sent from the application program to the linkservice when a node is closed by the user.
MESSHEADER "\Subject ClosingNode" "\NodeId "<NodeId>
The linkservice might send this message for instance as the result of a follow link from another application. Note the Location tag; it defines where the document is located and therefore allows the CSF or the linkservice to know how to interpret the NodeId. For further details on the issue of document management see Appendix C Content Specification.
MESSHEADER
"\Subject DisplayDocument"
"\NodeId "<NodeId>
"\Location " {"FileSystem" | "Internet"| "DMS" }
"\ReadOnly" {"True" | "False"}
Equally, location specifications might wanted to be displayed by the linkservice. This is done by sending the DisplayDataRef message; note that dataRefs have the attributes NodeId and location specification.
MESSHEADER "\Subject DisplayDataRef" "\DataRef " <DataRefId> "\PSpecId " <PSpecId>
This message is sent by the linkservice to a node that it wishes to automatically close e.g. in order to free a lock on a document.
MESSHEADER
"\Subject CloseNode"
"\NodeId "<NodeId>
"\UpdateNode "{"True" | "False"}
The application is then responsible for closing the node itself, ensuring that it has updated any anchors and its contents if required by the UpdateNode tag. In case of any errors the application program should send back an error message.
The "Error" message might be sent by any component. It is composed of the following structure:
MESSHEADER "\Subject Error" "\MessageId " <Id of message that caused the error> "\ErrorSubject " <the type of error that occurred> "\ErrorMessage " <the actual error string>
The definition of the location specifications has been quite a controversial issue during the development of this proposal (see thread "opaque locspecs"). The two main camps being the "opaque" people on one side and the "HyTime" people on the other end of the spectrum. The argument towards opaque location specification is that for the linkservice location specifications should be opaque because the link service does not actually deal with them but rather wants to handle them as uninterpreted byte blocks. The HyTime (HyTime, 1992) followers on the other hand argue that at some point you actually have to have a specification so that an application is able to locate a specific position within a document's multimedia content. And if you have to define it use an existing standard that has been developed in order to deal with location specifications in an abstract, platform independent way.
We have learned from both viewpoints and have concluded that both are right. Therefore, we do not treat location specifications as opaque but we allow components to do so by simply ignoring the specifications.
A number of additionally criteria have influenced our decision for the current definition of location specifiers:
As an example let us take the simplest data type, e.g. ASCII text. Most systems have developed similar fairly rich methods of locating strings. The location specification should include standards for these methods. Later, we might extend standards for such things as pictures, formatted text, videos etc. But opaque types will always be allowed and supported.
We also would like to stress the point that standardisation of location specifications is only partially subject to OHP. This can be compared to the situation with the document management protocol: strictly speaking this should not be part of the definition of OHP; however, if OHP should be really useful there have to be some common assumptions about both location specifications and document management functionality. For the current version of OHP we therefore provide these features so that OHP as a protocol can be implemented.
Now that we have explained in general our decisions we are able to define location specifications as part of OHP.
LOCSPEC = "\ContentType " <type, e.g., ASCII, binary> "\Content " <Mime encoded text string> LOC "\EndLocSpec "
Location specifications consist of a content type, the content itself as well as the actual location data. LOC is defined as
Loc = { NAMELOC | DATALOC | TREELOC | PATHLOC | SCRIPTLOC | NALOC }
In the following subsections we will explain these different basic types of location specifications. Again, it is up to the developers to introduce their own additional location specifications or to add additional tags where necessary for specific applications. For most cases though, the proposed set of location specifications should be sufficient.
Name space locations are used to reference an object by its name. The definition of name locations is as follows:
NAMELOC = "\LocType NameLoc"
So-called data locations are co-ordinate locations, i.e., objects are addressed by their relative position to another object. Data locations will be heavily used by OHP as most systems define dataRefs by relative positioning, for instance by keeping an offset. In order to know how this dimension specification should be interpreted, i.e. to get its data type, a quantum tag is defined. Count list follows the HyTime semantics of defining a dimension list. In particular, two markers define beginning and end of a node on an axis thus resulting in (number of axes * 2) markers.
A reverse counter is kept in order to do cross checking of validity of anchors. In case the expected object still can not be found an overrun behaviour can be specified: the error can simply be ignored, the markers can be truncated to the last unit on the axis or an error can be raised.
The HyTime time quantum "utc" expects items in the form yyyy-mm-dd hh:mm:ss.decimal, e.g., 1997-09-24 17:07:22.6122.
DATALOC =
"\LocType DataLoc"
"\Quantum " { "string" | "int" | "byte" | "utc" }
"\CountList " <list of Strings being interpreted by the application
program>
"\RevCountList " <list of Strings being interpreted by the application>
"\Overrun " { "ignore" | "error" | "trunc" }
Tree locations can be used for addressing a single object within a tree. The addressing is done in a way that on each level of the tree an object is selected by its position. These position numbers are expressed in CountList. For example a count list of "1 2 3" applied to an object referencing a book would get the third section of the second chapter of the book (assuming that a book has a structure with chapters and sections).
TREELOC =
"\LocType TreeLoc"
"\Overrun " { "ignore" | "error" | "trunc" }
"\CountList " <list of numbers>
As opposed to tree locations path locations are used to address a range of nodes by a path. This is done by addressing a tree as though it were a matrix in which the rows are the levels of the tree and the columns are the paths. Therefore the count list of a path location consists of an even number of pairs: the first pair identifies the columns (i.e. the paths to the leaves) and the second pair selects the rows.
PATHLOC =
"\LocType PathLoc"
"\NodeId " <NodeId>
"\Overrun " { "ignore" | "error" | "trunc" }
"\CountList " <list of numbers>
OHP does not define a specific query mechanism for addressing locations (as does for instance HyTime with the standard DSSSL Query Language, SDQ). However, by allowing script locations we define a way for those hypertext systems that use scripts to identify and address locations at the client's side.
SCRIPTLOC = "\LocType ScriptLoc" "\ScriptId <ScriptId>
An idea borrowed from HyTime is to address data that is currently not accessible. This could be a printed book which is not available on-line, a radio broadcast or even a person or an organisation. The point is that it might in some cases make sense to reference these nodes without having a application program for them. Instead, the application program could display a notification string, stating for example where to find a book in a shelf in a library. We call this location specification NALoc for "not accessible" location.
NALOC = "\LocType NALoc" "\Location " <string as description of the object and its physical location>
Many systems incorporate the possibility of displaying persistent selections in different ways. For example, persistent selections in text might be coloured blue, or some other colour, and areas of bitmaps might be shaded, raised or outlined; some systems support buttons that are not shown, or are only shown when the pointer is over them. In general this is a user choice, and it applies to all the persistent selections in the view, so may be a setting on the viewer that is completely independent of the linkservice.
However, there are cases where an author may wish particular persistent selections to show in some way that is different from others. In this case it is possible for the viewer to allow the specification of some particular presentation of the selection, and to store this along with the LocSpec, so that when it is viewed later, it will have the desired appearance. If this were the only requirement, the syntax and semantics of the presentation specifier would belong only to the viewer.
Unfortunately, there are many cases where the linkservice may wish, as the result of some script, to change the presentation, and the linkservice will not know the presentation unless it is part of the standard.
For the purpose of this version of the protocol we suggest that the information about presentation is kept application program specific. i.e. the application program may ask to store any presentation information in any form that it chooses, and the viewer will interpret this data at a later stage when asked to present the data again.
The consequence of this policy will be that the linkservice will not be able to communicate to the application program that it should change any presentation (e.g. as the result of a script) since it will not know the syntax of the presentation tag for this particular application program.
We are aware that strictly speaking presentation styles should not be defined within OHP (Anderson, 1997). However, as is true for the document management part and also for the location specifications, in order to make OHP really useable in the first phase a standardised agreed way of expressing presentation specifics has to be found.
PSPEC = "\PSpec " "\Name " <a string> ["\Colour " <colour>] ["\Style " <style>] ["\Visibility " "true" | "false"] "\endPSpec "
Following the original proposal we suggest a triplet of colour, style, visibility, each of which is optional. The above definition allows us to only put these things if we have them, and we could also add other tags if needed. We will define some tag values which will be understood.
We assume that the eight primary computer colours are supported, i.e. black, blue, cyan, white, magenta, green, red and yellow.
As minimal subset of styles we define flashing, bold, italic, outlined and shaded.
We recommend that the following definition for CONTENTSPEC be used, until such time as further work has improved on this.
CONTENTSPEC =
"\ContentSpec "
"\Name " <the content's name, typically a file name, a URL or a DMS
handle>
"\Location " "FileSystem" | "Internet" | "DMS"
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
"\EndContentSpec "
For example we might have
\ContentSpec \Name N:\\DOCS\\FILE.TXT \Location FileSystem
\Attributes
\Name owner \Value hcd
\EndAttributes
\EndContentSpec
or
\ContentSpec
\Name http://www.ecs.soton.ac.uk/~hcd
\Location Internet
\EndContentSpec
As far as the linkservice is concerned the CONTENTSPEC information is opaque. It stores the string, and when the node is required it sends this back. The client side is expected to provide some component which will be able to interpret this string in the cases where the client is asked to display a document. Typically this will be the CSF, which will then organise to actually get the document from the file system or the Internet or the document management system that it is using (which may actually be the linkservice itself if the linkservice is a hyperbase).
The following scenario is entitled "Navigational 1" (Nürnberg & Leggett, 1997). It is based on the idea that users want to build and/or browse "associations" between parts of data objects handled by their applications. Associations should be grouped into sets; whole association sets as well as single items in association sets might be created, deleted, opened, closed or merged. Following the analysis given by the authors of "Navigational 1" we will go through the goals of the scenario step by step.
In order to better demonstrate how OHP could be used for dealing with the requirements arising by the above scenario, we will assume the following subset of actions that show how to use OHP for navigation. This scenario is also available from the Java applet below by selecting "Navigational 1" from the choice menu.
Let's assume a user has started up his favourite text editor, selects a string and wants to follow any links associated with the selected string (for the scenario we assume that the answer includes simply one endpoint, though OHP would be able to deal with more than one endpoint). The ExecuteEndpoint message results in an endpoint referring to a spreadsheet file; the user's favourite spreadsheet application is launched and the file opened. The user selects one of the cells in the spreadsheet, defines it as an endpoint, switches to an e-mail client, selects an e-mail message and defines this message as an endpoint again. In a further step the user creates an association between the two endpoints using an application independent application allowing her/him to do so (this application could be part of the user interface component of the CSF).
Please note that references to Internet resources are annoted with a date showing the day when these references where checked for their validity the last time.
Anderson, K.M. A Critique of the Open Hypermedia Protocol. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www .cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Andrews K., Kappe, F. & Maurer, H. Hyper-G: Towards the Next Generation of Network Information Technology. Journal of Universal Computer Science, April 1995.
Aßfalg, R. (ed.). The Proceedings of the Workshop on Open Hypertext Systems, Konstanz, May 1994.
Davis, H.C., Hall, W., Heath, I., Hill, G. & Wilkins, R. Towards an Integrated Information Environment with Open Hypermedia Systems. In: D. Lucarella, J. Nanard, M. Nanard, P. Paolini. eds. The Proceedings of the ACM Conference on Hypertext, ECHT '92 Milano, pp 181-190. ACM Press, 1992.
Davis, H.C., Knight, S.K. & Hall, W. Light Hypermedia link services: A Study in Third Party Application Integration. In: The ACM Conference on Hypermedia Technology, ECHT '94 Proceedings. pp 41-50. ACM. Sept. 1994.
Davis, H., Lewis, A. & Rizk, A. OHP: A Draft Proposal for a Standard Open Hypermedia Protocol (Levels 0 and 1: Revision 1.2 - 13th March. 1996). 2nd Workshop on Open Hypermedia Systems, Washington, March 1996. Available as http://www.ecs.soton.ac.u k/~hcd/protweb.htm [1997 October 15].
Davis, H. Channels in OHP. Thread in OHS Mailing List (1997 June 6) Available as http://www.csdl.tamu.e du/ohs/archive/0032.html [1997 October 15].
Goose, S., Lewis, A. & Davis, H. OHRA: Towards an Open Hypermedia Reference Architecture and a Migration Path for Existing Systems. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www .cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Grønbæk K. & Trigg, R.H. Design Issues for a Dexter-Based Hypermedia System. In: D. Lucarella, J. Nanard, M. Nanard, P. Paolini. eds. The Proceedings of the ACM Conference on Hypertext, ECHT '92 Milano, pp 191-200. ACM Press. Nov. 1992.
Grønbæk, K. & Trigg, R.H. Toward a Dexter-based model for open hypermedia: Unifying embedded references and link objects. In: The Proceedings of Hypertext '96. ACM 1996. Available as http://ww w.cs.unc.edu/~barman/HT96/P71/Groenbaek-Trigg.html [1997 October 15].
Grønbæk, K. & Wiil, U.K. Towards a Reference Architecture for Open Hypermedia. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www .cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Halasz, F. & Mayer, S. (edited by Grønbæk, K. & Trigg, R.H). The Dexter Hypertext Reference Model. Communications of the ACM. pp 30-39. 37(2). Feb. 1994.
Hamilton, G. (ed.) JavaBeans 1.01 Sun Microsystems, July 97. Available as http://www.javasoft.com/be ans/beans.101.ps [1997 October 15].
Haake, J. Collaboration via OHS. A Scenario available from the OHS Working Group Scenario Page http://www.csdl.tamu.e du/ohs/scenarios/collab/ [1997 October 15].
ISO - International Organization for Standardization: Information Technology - Hypermedia/Time-based Structuring Language (HyTime), ISO/IEC 10744, 1992.
Kacmar, C.J. & Leggett, J.J. PROXHY: A Process-Oriented Extensible Hypertext Architecture. ACM Trans. on Information Systems, 9(4) pp. 299-419. Oct. 1991.
Marshall, C. C., Shipman, III, F. M. & Coombs, J. H.VIKI: Spatial Hypertext Supporting Emergent Structure, Proceedings of the 1994 European Conference on Hypertext, ACM, 1994.
McKeown, Michael T. URL Monikers and ActiveX Hyperlinks. Microsoft Developer Relations Group, May 1996. Available as http:// www.microsoft.com/workshop/prog/prog-gen/moniker-f.htm [1997 October 15].
Nielsen, H.F. PEP - an Extension Mechanism for HTTP. W3C Working Draft 28 April 1997. Edited by Henrik Frystyk Nielsen. Available as http://www.w3.org/TR/WD-http- pep-970428 [1997 October 15].
Nürnberg, P. opaque locspecs. Thread in OHS Mailing List (1997 April 17). Available as http://www.csdl.tamu.e du/ohs/archive/0023.html [1997 October 15].
Nürnberg, P. & Leggett, J. Navigational 1. A Scenario available from the OHS Working Group Scenario Page http://www.csdl.tamu.edu /ohs/scenarios/nav1/ [1997 October 15].
Open Document Management API (ODMA) Open Document Management API Version 1.5. Available as http://www.aiim.org/odma/odma15.h tm [1997 October 15].
Object Management Group (OMG) Relationship Service Specification. OMG Document 94-5-5, Bull, HP, Olivetti, IBM, Siemens, & SunSoft; May 30, 1994. Available as http://www.mitre.org/research/domis/omg/services/relationships-94-5-5.ps [1997 October 15].
Object Management Group (OMG) CORBA 2.0/IIOP Specification. OMG Document 97-09-01, August, 1997. Available as ftp://ftp.omg.org/pub/ docs/formal/97-09-01.pdf [1997 October 15].
Østerbye, K. & Wiil, U.K. The Flag Taxonomy of Open Hypermedia SystemsIn: The Proceedings of the ACM Conference on Hypertext '96, Washington D.C. ACM Press. March 1996. Available as http://www.cs.unc.e du/~barman/HT96/P51/Flag.ps.gz [1997 October 15].
Pam, A. Fine-Grained Transclusion in the
Hypertext Markup Language. Available as
http://xanadu.com.au/xanadu/draft-pam-html-fine-trans-00
.txt;internal&sk=1A3F7418950 [1997 October 15].
Reich, S. How OHP's LocSpecs could benefit from ISO/IEC 10744. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www .cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Rizk, A. The M2000 Protocol Description Manual. Euroclid, France. Available from the Author. 1991.
Rizk, A. & Sauter, L. Multicard: An Open Hypermedia System. In: D. Lucarella, J. Nanard, M. Nanard, P. Paolini. eds. The Proceedings of the ACM Conference on Hypertext, ECHT '92 Milano, Italy, December 1992, pp. 181-190. ACM Press. 1992.
Taylor, R. N. Response: A Draft Proposal for a Standard Open Hypermedia Protocol. 2nd Workshop on Open Hypermedia Systems, Washington, March 1996. Available from the Author.
IETF WEBDAV Working Group. World Wide Web Distributed Authoring and Versioning. Available as http://www.ics.uci.edu/~ejw/au thoring/, [1997 October 15].
Wiil, U.K & Østerbye, K. (eds.). The Proceedings of the ECHT '94 Workshop on Open Hypermedia Systems, Edinburgh, Sept. 1994. Technical Report R-94-2038. Aalborg University. Oct. 1994.
Wiil, U.K. & Leggett, J. The HyperDisco Approach to Open Hypermedia Systems. In: The Proceedings of the ACM Conference on Hypertext '96, Washington D.C., pp. 140-148. ACM Press. March 1996. Available as http://www.cs .unc.edu/~barman/HT96/P11/HyperDisco.ps.gz [1997 October 15].
Wiil, U.K. The Proceedings of the 2nd Workshop on Open Hypermedia Systems. Available as http://www.daimi.aau.dk/~kock /OHS-HT96/, Washington D.C., March 1996. [1997 October 15].
Wiil, U.K. The Proceedings of the 3rd Workshop on Open Hypermedia Systems. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www .cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Wiil, U.K. & Whitehead, J.E. Interoperability and Open Hypermedia Systems. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www .cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].