
Fig. 1: Hypertext Data Model.
Editors
Hugh Davis
The Multimedia Research Group
Dept. of Electronics and Computer Science
The University of Southampton
UK, SO 17 1BJ
email hcd@ecs.soton.ac.uk
Sigi Reich*
Dept. of Information Systems
University of Linz
A-4040 Linz, Austria
email sre@ifs.uni-linz.ac.at
David Millard
The Multimedia Research Group
Dept. of Electronics and Computer Science
The University of Southampton
UK, SO 17 1BJ
email dem@soton.ac.uk
Reporting work undertaken by the Open Hypermedia Systems Working Group including
Kenneth
M. Anderson, University of
California-Irvine, USA
Stuart Goose,
Siemens Corporate Research, US
Kaj
Grønbæk, University of Århus, Denmark
Jörg M. Haake,
GMD-IPSI, Darmstadt, Germany.
Andy Lewis,
University of Southampton, UK
Peter
J. Nürnberg, University of Århus,
Denmark
Niels Oluf Bouvin,
Aarhus University, Denmark
Kasper Østerbye,
Aalborg University, Denmark.
Andrew Pam,
Xanadu, Australia
Lloyd Rutledge,
CWI, Amsterdam, The Netherlands
Antoine Rizk,
Euroclid, France
Richard Taylor,
University of California Irvine, USA
Randall
H. Trigg, Xerox PARC, USA
Uffe
K. Wiil, University of Århus, Denmark
There have been a number of "open" hypertext systems discussed in the literature, but as yet these systems do not inter-operate. Meanwhile, the World Wide Web has been universally adopted, and part of this success must be attributed to the open protocols, which have allowed system developers to produce their own servers and clients which inter-operate with others. This paper presents a general data model for hypertext and proposes a standard protocol for client side applications to communicate with link servers for the purpose of storing, retrieving and navigating hypertext objects. Adoption of this protocol would enable developers and researchers to re-use standard viewers and link servers within their systems.
At the first workshop on open hypermedia systems (OHS 1) in Edinburgh at ECHT'94, Antoine Rizk proposed the standardization of a lightweight protocol that would allow a client program to talk to a link server. The benefit that was expected was that the OHS group would be able to start experimenting with interoperability between link servers and reduce the overhead of re-implementing viewers. It was intended that this protocol would be simple enough that a third party application such as Word for Windows could be simply adapted using the built in macro programming facilities. A first draft of such an open hypertext protocol (OHP) (Davis et al, 1996) was presented at OHS 2 at Hypertext '96, and two subsequent meetings of a working group have refined and altered the protocol significantly.
The original protocol had attempted to capture that common set of navigational "point and click" actions that are embodied in most traditional hypertext systems. The protocol was a common subset. At OHS 3.5 in September 97 the group decided that the protocol should attempt to become a superset that could express the actions that occur in all structure processing systems. We imagined a set of "hypertext objects" which are stored on structure servers, and a set of interfaces that allow us to manipulate these objects. In this world this protocol becomes the "navigational hypertext interface" (a subset of the OHP protocol) and the objects in the data model (links, nodes etc), are "navigational hypertext objects" which are a subclass of the set of all objects.
This paper does not attempt to map the original OHP onto this model, but continues to present the protocol as an ASCII string based protocol similar, for example, to http. From the point of view of the protocol it is not important to discuss the underlying representation of the messages, but only their content. However, if the goal of interoperability is to be achieved eventually, we will have to agree the "on the wire" issues.
For the purpose of this paper, OHP is assumed to refer only to the navigational interface of the full protocol.
This version of the protocol has grown much "fatter" than the earlier version, reflecting the group's desire to aim towards a protocol that could represent all navigational hypertext features, rather than a subset.
Those unfamiliar with the nature of the interactions that occur with link servers are advised to look at the original proposal, which contains a number of scenarios. This paper is intended to represent the current state of the protocol
The hypertext community has invested much time and effort in attempting to define hypermedia, and probably the most successful result is the Dexter model ( Halasz & Mayer, 1994, Grønbæk & Trigg, 1996). In this section we define the terminology and model that is assumed by the OHS working group.
This description attempts to be as inclusive as possible in the sense that the model is capable of representing the link models assumed by most existing hypertext systems.
However, we are not attempting to model the systems that have particular features such as transclusions in Xanadu (Pam, 1997) or spatial hypertext systems (Marshall, 1994). These systems will probably need to design their own interfaces.
The complete data model will appear more complex than that of many existing systems, but the reader should understand that it will not always be necessary to expose the user to this complexity.
Figure 1 depicts the basic entities of the hypertext data model, and their relationships.
The model of hypertext assumed in this paper consists of servers which hold links, endpoints, references and nodes. Each of these objects have unique identifiers within the system. Servers which manage these objects are known as link servers.
A link is an object which represents a connection between zero or many endpoints. A link may (or may not) have a type (e.g. "defines"). In many systems traversing a link may cause some process to run as well as or instead of causing the focus to move to some point at the end of the link. For example Figure 2 shows two links, one of which has three endpoints and type "defines", and the other which has two endpoints and type "supports".
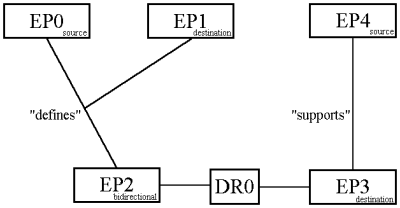
Fig. 2: Example of Data Model.
An endpoint is an object which holds the attributes of the end of a link. Typically an endpoint will hold a traversable direction which might be source, destination or bi directional. For example, in Figure 2, the link "defines" may be traversed from EP0 to EP1 and EP2, and it may be traversed from EP2 to EP1, but it will not be possible to traverse this link from EP1.
A dataRef defines the node and the point within that node at which the application which shows the data (viewer / editor) should indicate some kind of persistent selection which will be a hypertext "hotspot". We have deliberately avoided the use of the words "anchor" and "button" as these terms have been somewhat overloaded in the past. A dataRef therefore consists of a nodeSpec and a location specifier or LOCSPEC. A dataRef may be associated with zero or more endpoints. For example, a user may make a number of dataRefs before associating any of them with any endpoint of any link. Also, one dataRef might refer to more than one endpoint, and these endpoints might belong to different links. For example dataRef DR0 in Figure 2 is associated with both EP2 and EP3.
A nodeSpec will resolve to one or more node identifiers (nodeID's) which will each uniquely identify one node.
A node is a wrapper object which holds the meta-data about some content data including the information about where to find the file or files which make up that content data. This content data is defined by a content specification or CONTENTSPEC.
A location specifier (LOCSPEC) holds the information that defines the position at which the persistent selection should be displayed as well as any presentation information.
A presentation specifier (or PSPEC) may be associated with any hypertext object and defines how that object should be displayed at run time.
Sometimes a link or dataRef may have an associated script specifier (SCRIPTSPEC) which is executed when the link or reference is used.
In the above definitions, the terms CONTENTSPEC, LOCSPEC, SCRIPTSPEC and PSPEC have all been shown in uppercase. This is to signify that their definition is outside the scope of the navigational hypertext protocol and that they are therefore opaque, whereas all terms shown in lowercase are fully defined within the data model. However, within the scope of the suggested protocol shown in the Appendices we made some proposals for possible realizations of these opaque objects.
If a link server stores the content data as well as the hypertext objects, then it may be referred to as a hyperbase, since it is a database storing the entire set of objects involved in the hypertext.
A link server is expected to provide a core set of link services which involve the creation, retrieval and use of links, endpoints, dataRefs, nodes, scripts and presentations. It will also be expected to provide some level of document management, for example, informing the client the name of the file it must load and display in order to complete a link traversal.
Many link servers provide extra services, which assist the user in navigation, such as Microcosm's integrated search engine which creates dynamic links.
Addressing interoperability not only requires some common understanding of the data model; also the underlying architecture should be investigated and agreed upon. This is because the data model usually makes assumptions about the architecture and because functionality and behavior are to a large extent based on the architecture. Therefore we will discuss general assumptions about the underlying architecture of open hypermedia systems. We will try to be as general as possible in doing so but we will not attempt to define a reference architecture. There is already some promising work in this area (Goose et al., 1997, Grønbæk & Wiil, 1997, Wiil & Whitehead, 1997) and we will only describe what we think is the minimum necessary to allow an implementation of the above data model.
There is a problem that impedes the simplicity of a model which has the application program communicating directly with the link server. In practice all those who have implemented link servers have identified the need for some component on the client side which is present throughout the hypertext session. (Goose et al., 1997) call it the "Runtime", (Wiil and Leggett, 1996) call it the "Tool Integrator" and in the original version of this protocol (Davis et al., 1996) it was called the "Communication Protocol Shim". However, we prefer, now, to call it the CSF. (This acronym might be said to stand for "Client Side Functions"; actually it originally stood for "Client Side Foo", which was the "stub" name adopted by the group in order to prevent any further argument about the name). Figure 3 gives a graphical representation.
The responsibilities of the CSF will always include starting an application (with its data) when required to by the link server (e.g. as the result of traversing a link to a document which must be handled by some application which is not currently running). This function is necessary as in heterogeneous systems it is not always possible for a server application to start a client on a remote machine.
There are many other tasks that might need to be carried out on the client side, such as
For the above reasons we believe that it is necessary that some of the communications between client side applications and link servers are routed through the CSF. The exact routing of the messages is irrelevant from the point of view of the link server, which simply receives the messages and sends replies. However, if we want to allow third party viewers to plug in to a CSF, there will need to be some standardization so that the viewer can know which services to expect the CSF to provide. For example some systems may the CSF to intercept and handle all requests to produce content so that they can proxy for the document management system.

Fig. 3: Usage of Shims for Interoperability.
Figure 3 gives an example of the kind of architecture we are assuming. In this figure there are two client side applications. One is Word, which has been adapted as a OHP aware viewer using its macro language, and one is a special purpose picture viewer which was written to work with OHP. Both these communicate with the linkservers via the CSF using the OHP protocol. One of the servers is a native OHP server, whereas the other might be a DHM (DeVise Hypermedia) server, and a shim has been inserted in order to convert the OHP protocol to the DHM native protocol.
Besides the components application program, link server and CSF there is a fourth component, the Document Management System (DMS). We are convinced that an additional protocol - a document management protocol (DMP) - should allow standardized communication to document management systems. The Open Document Management API (Open Document Management, 1997) could serve as a good example and some of the concepts in the hypertext data model, e.g. the definition of a NodeId as a unique document identifier, follow this proposal.
The reader should note that Figure 3 shows the client communicating with multiple servers. At this stage we have not defined whether this is on a "one server per session" basis, or whether we expect the client to be able to send requests to distributed servers, as a web browser talks to multiple servers. We expect to experiment with such architectures.
In order to define the mechanics of OHP we will follow a Backus-Naur Form (EBNF) as is for instance done in Internet drafts. We use the following constructs:
name = definition: The name of a rule is
simply the name itself and is separated from its
definition by the equal "=" character. "literal": defines a literal. The
definition is case sensitive. {elem1 | elem2}: a "|" can be used
to define either/or alternatives. {elem}*: A "*" indicates
repetition, i.e. there can be any number of occurrences. {elem}+: A "+" indicates that one
or more elements have to be present, i.e. there has to be
at least one element. [elem]: Square brackets enclose optional
elements. <elem>: Angle brackets enclose basic
types that are not specified in more detail but can be
dealt with by the receiving/sending components. ELEM: In the case where an element type is
declared in capital letters this declaration can be seen
as a placeholder that is defined somewhere else and just
referred to at the current location. It may or may not
represent an opaque (see section 4.2).
Additionally we assume the following rules (the US-ASCII coded character set is defined by ANSI X3.4-1986):
CHAR = US-ASCII character (octets 0 - 127) UPALPHA = any US-ASCII uppercase letter
"A".."Z" LOALPHA = any US-ASCII lowercase letter
"a".."z" ALPHA = UPALPHA | LOALPHA DIGIT = any US-ASCII digit
"0".."9" CTL = any US-ASCII control character (octets
0 - 31) and DEL (127) CR = US-ASCII CR, carriage return (13) LF = US-ASCII LF, linefeed (10) SP = US-ASCII SP, space (32) OHP messages will consist of text strings (CHAR). In the following sections the messages are shown formatted on multiple lines for ease of presentation. However, the messages themselves will be one continuous stream of ASCII text, unbroken by line feeds (LF). The messages consist of Tags, which are proceeded by a backslash ('\') and succeeded by a white space (SP). The characters that follow, up to the next tag or the end of the message are the tag contents. A tag content may be empty. In addition some tags denote a block of the message with some particular relevance. E.g. \LocSpec and \EndLocSpec.
The tags that should occur in each message are explained in the protocol definition. They may be presented in any order. The protocol is designed such that if tags are missing, the system will attempt to work with the remaining information, and if extra undefined tags are present, systems that do not understand these tags will simply ignore them. If a backslash ('\') occurs within the tag content, then it should be quoted by preceding it with a further backslash.
As opposed to the previous draft of OHP (Davis et al., 1996), which defines a channel as an identifier for messages, we have defined a dedicated message header (see Thread "Channels in OHP" of OHS discussion list). As already mentioned above, OHP abstracts from the communication layer so the header does not include any host or port or other communication specific information.
Every message will have a message header. A message header will contain information about the transaction that both sides of the communication channel may from time to time need to examine. It is not immediately clear that all of this information is essential, but there is a general consensus that parts of this information will, at times, be necessary.
MessageHeader = MessageID ReturnMID VersionID SessionId UserID. MessageID = "\MID " <a unique identifier for the particular message>
Probably this will be realised by a time stamp.
ReturnMId = "\RMID " <the ID of the message this message is a reply to>
The RMID allows applications and link servers to keep track of sent and received messages and by that keep state. This field can be left empty in case a message is sent that is not a reply to a previous message.
VersionId = "\VID " <current version of the protocol>
E.g. "2.1.Southampton" would indicate version 2.1 of the OHP protocol with Southampton extensions. The X.X part is essential, and the remainder can be ignored.
SessionId = "\SID " <a system dependant string which uniquely identifies
some "transaction" or "session">
We have not yet defined what a session is and we envisage that this will become significant when we attempt to deal with collaboration issues. Yet it is importtant for the protocol to give basic support and thus we provide the session ID.
UserID = "\UID " <a system dependant string uniquely identifying the user>
There are certain entities within OHP that are treated as opaque (these appear within the protocol in uppercase). This means that their definition is unimportant for the specification of OHP itself although they will need to be understood by the applications using OHP. There are four opaques within the current protocol, and suggested specifications are in the Appendices (Appendix A : LOCSPEC, Appendix B : PSPEC, Appendix C : CONTENTSPEC and Appendix D : SCRIPTSPEC). We expect a situation where a general definition of an opaque is needed (to allow interoperability) but where the protocol must be flexible enough to allow specialist applications to define their own standards for these opaques and to insert an appropriate byte stream; in order for such a byte stream to be placed within in ASCII protocol, it would be necessary to MIME encode the bytes.
So that an application (or the CSF) can parse all opaques, each opaque is accompanied by a version ID and enclosed within a begin and end tag. Thus a parser can check the version and skip the opaque if it is not one that is understood.
There are two main classes of messages to be considered; those sent by the application program and those sent by the link server. The messages sent by the link server are always answers to messages that have been sent by a client. However, in a co-operative working environment we cannot rule out the possibility that the server sends a message to client B in response to a message from client A.
The following table gives an overview of the basic messages that form the OHP protocol. The very left column defines the basic entities we have identified, i.e. link, endpoint, dataRef, node, script, presentation specification (PSPEC) and services; the top line, i.e. the columns' labels, define the basic functions that can be processed on these entities. The functions are create, get, update, delete. Lists are introduced as a means to allow aggregation of entities. An endpoint table for example would be dealt with in OHP as a list of endpoints.
Create |
Get |
Update |
Delete |
Execute |
Notification |
|
Endpoint |
X |
X |
X |
X |
X |
|
DataRef |
X |
X |
X |
X |
||
Link |
X |
X |
X |
X |
||
Node |
X |
X |
X |
X |
ClosingNode |
|
Script |
X |
X |
X |
X |
X |
|
PSpec |
X |
X |
X |
X |
||
Services |
X |
Table 1: OHP Client Message Table
The following messages may be sent by the link server:
Definition |
Display |
Execute |
Close |
|
Endpoint |
X |
X |
||
DataRef |
X |
X |
||
Link |
X |
|||
Node |
X |
X |
X |
|
Script |
X |
X |
||
PSpec |
X |
|||
Services |
X |
Table 2: OHP Server Message Table
The Error message might be sent by any component being involved in an OHP session.
We will now present the messages in detail and also give examples or additional comments where necessary to understand the semantics of the protocol.
Note that some of the messages might be rarely used, some even never. However, for reasons of consistency and symmetry of the protocol we defined and kept them as part of the standard.
When a new endpoint has been created, the application program will send the following message to the link server. Generally an endpoint will require a dataRef. Also the PSpec and Service tags may well be defaults (e.g. 'blue' and 'follow link' respectively). Note, that not only an application program but also processes or scripts can create endpoints by sending this message.
MESSHEADER
"\Subject CreateEndpoint"
"\DataRefId " <DataRefId>
"\Direction " "Source" | "Destination" | "Bidirectional"
"\Service " <ServiceNmae>
"\PSpecId " <PSpecId>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
This message allows the application program to ask the link server for the current details of the endpoint identified.
MESSHEADER "\Subject GetEndpoint" "\EndpointId " <EndpointId>
Both messages, CreateEndpoint and GetEndpoint should be answered by the link server with an EndpointDef message.
Updates an endpoint's attributes given its ID.
MESSHEADER
"\Subject UpdateEndpoint"
"\EndpointId " <EndpointId>
"\DataRefId " <DataRefId>
"\Direction " "Source" | "Destination" | "Bidirectional"
"\Service " <Service>
"\PSpecId " <PSpecId>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes an endpoint given its ID.
MESSHEADER "\Subject DeleteEndpoint" "\EndpointId " <EndpointId>
The application program, while running, is expected to maintain the list of endpoints. It may obtain this list, for a given node, by sending the following message.
MESSHEADER "\Subject GetEndpointList" "\NodeId " <NodeId>
The link server will reply by sending a "EndpointListDef" message.
When an endpoint is activated (e.g. clicked ) the following message will be sent to the link server to request that whatever action is associated with that endpoint (e.g. follow link) will be performed by the link server.
MESSHEADER "\Subject ExecuteEndpoint" "\EndpointId " <EndpointId>
This message is sent by the link server on request from an application program (CreateEndpoint or GetEndpoint), or possibly the link server might send this autonomously in the case where a new endpoint has been made by a user in a different session. The tag "\Attributes" is a list of attribute name and value pairs that contain all the attributes the link server knows about this object.
MESSHEADER
"\Subject EndpointDef"
"\EndpointId " <EndpointId>
"\DataRefId " <DataRefId>
"\Direction " "Source" | "Destination" | "Bidirectional"
"\Service " <Service>
"\PSpecId " <PSpecId>
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
Sent by the link server on request from an application program (endpoint).
MESSHEADER
"\Subject EndpointListDef"
{"\Endpoints "
"\EndpointId " <EndpointId>
"\DataRefId " <DataRefId>
"\Direction " "Source" | "Destination" | "Bidirectional"
"\Service " <ServiceName>
"\PSpecId " <PSpecId>
"\Attributes "
{"\Name "<the attribute's name>
"\Value "<its value>}*
"\EndAttributes "
"\EndEndpoints "}*
The link server might request from the application program to display an endpoint ("hotspot") for example, as the end of a link that has been followed.
MESSHEADER "\Subject DisplayEndpoint" "\EndpointId " <EndpointId> "\PSpecId " <PSpecId>
DataRefs encapsulate attributes for location specifications and the node itself. Some systems will require dataRefs to be created automatically when an endpoint is created; others with more complex user interfaces might allow users to create dataRefs and connect them to endpoints. Note that not only users but also system processes (including scripts) might create dataRefs.
MESSHEADER
"\Subject CreateDataRef"
"\NodeId " <NodeId>
"\LocSpecVID " <LocSpecVersionID>
"\LocSpec "
LOCSPEC
"\EndLocSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
This message allows the application program to ask the link server for the current details of the dataRefs identified.
MESSHEADER "\Subject GetDataRef" "\DataRefId " <DataRefId>
Both messages, Create DataRef and Get DataRef should be answered by the link server with a DataRefDef message.
Updates a dataRef's attributes given its ID.
MESSHEADER
"\Subject UpdateDataRef"
"\DataRefId " <DataRefId>
"\NodeId " <NodeId>
"\LocSpecVID " <LocSpecVersionID>
"\LocSpec "
LOCSPEC
"\EndLocSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes a dataRef given its ID.
MESSHEADER "\Subject DeleteDataRef" "\DataRefId " <DataRefId>
This message is sent by the link server on request from an application program (CreateDataRef or GetDataRef). In the case where a new endpoint has been made by a user in a different session, the link server might send this autonomously. The tag "\Attributes" is a list of attribute name and value pairs that contain all the attributes the link server knows about this object.
MESSHEADER
"\Subject DataRefDef"
"\DataRefId " <DataRefId>
"\NodeId " <NodeId>
"\LocSpecVID " <LocSpecVersionID>
"\LocSpec "
LOCSPEC
"\EndLocSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
The next set of messages is concerned with the manipulation of links. In practice most application programs used for viewing data will not handle links, but only endpoints. This set of messages is provided partly in order to provide a symmetric set of messages handling all objects within the link server. However, we can envisage the case where a developer may wish to produce client side tools for the creation, manipulation and editing of links. From the point of view of the link server, it is unimportant whether the messages come from an application program or a link editor, and OHP should provide such messages.
MESSHEADER
"\Subject CreateLink"
"\Endpoints " {"\EndpointId " <EndpointId>}+ "\EndEndpoints "
"\Description " <Description>
"\Type " <Type>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Gets the attributes of a link given its ID. Both messages, CreateLink and GetLink should be answered by the link server with a LinkDef message.
MESSHEADER "\Subject GetLink" "\LinkId " <LinkId>
Updates a link's attributes given its ID.
MESSHEADER
"\Subject UpdateLink"
"\LinkId " <LinkId>
"\Endpoints " {"\EndpointId " <EndpointId>}+ "\EndEndpoints "
"\Description " <Description>
"\Type " <Type>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes a link given its ID.
MESSHEADER "\Subject DeleteLink" "\LinkId " <LinkId>
An application program may be interested in manipulating the list of all links. Note that future versions of OHP may include a context tag or a query tag in order to allow the client to specify which list of links to get. At present it will deliver all links in the link server.
MESSHEADER "\Subject GetLinkList"
The link server will reply by sending a "LinkListDef" message.
Sent by the link server on request from an application program (CreateLink and GetLink).
MESSHEADER
"\Subject LinkDef"
"\LinkId " <LinkId>
"\Endpoints " {"\EndpointId " <EndpointId>}+ "\EndEndpoints "
"\Description " <Description>
"\Type " <Type>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Sent by the link server on request from an application program (GetLinkList).
MESSHEADER
"\Subject LinkListDef"
{"\Links "
"\LinkId " <LinkId>
"\Endpoints " {"\EndpointId " <EndpointId>}+ "\EndEndpoints "
"\Description " <Description>
"\Type " <Type>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
"\EndLinks "}*
Again, as with links, we do not believe that the typical application program will be interested in manipulating nodes, but since nodes are handled by many link servers, it seems appropriate to provide an interface to these objects so that developers may produce client side tools to manipulate them, such as browsers. The reader is reminded that in this context a node is a wrapper object that contains the meta-data about a document (data content), rather than the document itself.
OHP is not a protocol for dealing with the actual storage and retrieval of documents. We assume that at some stage a protocol will be created for doing this (HTTP is actually one such protocol, if limited in some aspects; the Open Document Management API proposes another see Open Document Management API, 1997). Yet, actually managing content as is represented by documents is what will make OHP a useable protocol. For the moment we will therefore abstract in the definition of the protocol by using an opaque string representing a document ("CONTENTSPEC"). However, we also will make some assumptions about which components are going to deal with this string, and in what way. These are proposed in Appendix C Content Specification.
The following message will create a new node in the link server. This message is perhaps the one message related to nodes that might be used by an application program, in the case where a client side program had just loaded or created some new data content and wished to register it with the link server.
MESSHEADER
"\Subject CreateNode"
"\NodeName " <A title that the application may choose to display>
"\MimeType " <MimeType>
"\PreferredApp " <The name of the application which we would prefer to use
with this data>
"\ContentSpecVID " <ContentSpecVersionID>
"\ContentSpec "
CONTENTSPEC
"\EndContentSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Gets a node's attributes given its ID.
MESSHEADER "\Subject GetNode" "\NodeId " <NodeId>
Both messages, CreateNode and GetNode should be answered by the link server with a NodeDef message.
Updates a node's attributes given its ID.
MESSHEADER
"\Subject UpdateNode"
"\NodeId " <NodeId>
"\NodeName " <A title that the application may choose to display>
"\MimeType " <MimeType>
"\PreferredApp " <The name of the application which we would prefer to use
with this data>
"\ContentSpecVID " <ContentSpecVersionID>
"\ContentSpec "
CONTENTSPEC
"\EndContentSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes a node given its ID.
MESSHEADER "\Subject DeleteNode" "\NodeId " <NodeId>
An application program may be interested in manipulating the list of all nodes. Note that future versions of OHP might include a context tag or a query tag in order to allow the client to specify which list of nodes to get. At present it will deliver all nodes in the link server.
MESSHEADER "\Subject GetNodeList"
The link server will reply by sending a "NodeListDef" message.
Sent by the link server on request from an application program.
MESSHEADER
"\Subject NodeDef"
"\NodeId " <NodeId>
"\NodeName " <A title that the application may choose to display>
"\MimeType " <MimeType>
"\PreferredApp " <The name of the application which we would prefer to use
with this data>
"\ContentSpecVID " <ContentSpecVersionID>
"\ContentSpec "
CONTENTSPEC
"\EndContentSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Sent by the link server on request from an application program (GetNodeList).
MESSHEADER
"\Subject NodeListDef"
{"\Nodes "
"\NodeId " <NodeId>
"\NodeName " <A title that the application may choose to display>
"\MimeType " <MimeType>
"\PreferredApp " <name of the application which we would prefer to use
with this data>
"\ContentSpecVID " <ContentSpecVersionID>
"\ContentSpec "
CONTENTSPEC
"\EndContentSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
"\EndNodes "}*
Scripts play an important part in some hypermedia systems (e.g. Hypercard and Multicard), and are hardly used in others. Scripts may be classified into two types:
From the point of OHP, Scripts themselves are opaque. However it is useful to attempt some standardisation of the content of the Script. This is discussed in Appendix D.
This message is used to create a new script.
MESSHEADER
"\Subject CreateScript"
"\ScriptVID " <ScriptVersionID>
"\Script "
SCRIPTSPEC
"\EndScript "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Gets the attributes of a script given its ID. Both messages, CreateScript and GetScript should be answered by the link server with a ScriptDef message.
MESSHEADER "\Subject GetScript" "\ScriptId " <ScriptId>
Updates a script's attributes given its ID.
MESSHEADER
"\Subject UpdateScript"
"\ScriptId " <ScriptId>
"\ScriptVID " <ScriptVersionID>
"\Script "
SCRIPTSPEC
"\EndScript "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes a script given its ID.
MESSHEADER "\Subject DeleteScript" "\ScriptId " <ScriptId>
A client may send this message to the server, in which case the server will execute the given script, or a linkserver may send this message to a client, in which case, if the client does not currently have the script identified, it will need to send a GetScript message back, in order to execute the script on the client.
MESSHEADER "\Subject ExecuteScript" "\ScriptId " <ScriptId>
Sent by the link server on request from an application program.
MESSHEADER
"\Subject ScriptDef"
"\ScriptId " <ScriptId>
"\ScriptVID " <ScriptVersionID>
"\Script "
SCRIPTSPEC
"\EndScript "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Alternative presentation of hotspots is an important feature in some systems. OHP allows users to specify different presentations. From the point of view of OHP and linkservers, presentation specifiers (PSpecs) are opaque strings, which are interpreted by the application program. However, in order to allow for interoperability of application programs, and in order to allow server end scripts to change the presentation in a client, it is useful to attempt some standardisation of the content of the PSpec. This is discussed in Appendix B Presentation Specification.
Used to create a presentation specification.
MESSHEADER
"\Subject CreatePSpec"
"\PSpecVID " <PSpecVersionID>
"\PSpec "
PSPEC
"\EndPSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Returns a presentation specification's attributes given its ID. Both messages, CreatePSpec and GetPSpec should be answered by the link server with a PSpecDef message. This ID then can be used as parameter in further message calls.
MESSHEADER "\Subject GetPSpec" "\PSpecId " <PSpecId>
Updates a presentation specification's attributes given its ID.
MESSHEADER
"\Subject UpdatePSpec"
"\PSpecId " <PSpecId>
"\PSpecVID " <PSpecVersionID>
"\PSpec "
PSPEC
"\EndPSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Deletes a presentation specification given its ID.
MESSHEADER "\Subject DeletePSpec" "\PSpecId " <PSpecId>
Sent by the link server on request from an application program.
MESSHEADER
"\Subject PSpecDef"
"\PSpecId " <PSpecId>
"\PSpecVID " <PSpecVersionID>
"\PSpec "
PSPEC
"\EndPSpec "
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
The "GetServices" message is to be sent from application program to link server in order to know which additional services are available, above the standard set which manipulate dataRefs, endpoints, links, nodes and presentations. The link server should answer this request with a "ServicesDef" message. Services are defined by a description and a service name.
MESSHEADER "\Subject GetServices"
The ExecuteService message is a very general message that can be used by the application program to request a link server to do one of its services. The available services can be retrieved by the GetServices message.
MESSHEADER
"\Subject ExecuteService"
"\Service " <name of the service>
"\EndpointId " <EndpointId>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
Sent by the link server on request from an application program (GetServices).
MESSHEADER
"\Subject ServicesDef"
{"\Services "
"\Service " <name of the service>
"\Description " <a string which may be used to describe the service to a user>
"\EndServices " }*
The minimum reply should include the service named "FollowLink", which all link servers must handle. All other services are server dependant.
This message is sent from the application program to the link server when a node is closed by the user.
MESSHEADER "\Subject ClosingNode" "\NodeId "<NodeId>
The link server might send this message for instance as the result of a follow link from another application. For further details on the issue of document management see Appendix C Content Specification.
MESSHEADER
"\Subject DisplayNodeContent"
"\NodeId "<NodeId>
"\ReadOnly" {"True" | "False"}
Equally, location specifications might want to be displayed by the link server. This is done by sending the DisplayDataRef message; note that dataRefs have the attributes NodeId and location specification.
MESSHEADER "\Subject DisplayDataRef" "\DataRef " <DataRefId> "\PSpecId " <PSpecId>
This message is sent by the link server to a node that it wishes to automatically close e.g. in order to free a lock on a document.
MESSHEADER
"\Subject CloseNode"
"\NodeId "<NodeId>
"\UpdateNode "{"True" | "False"}
The application is then responsible for closing the node itself, ensuring that it has updated its contents if required by the UpdateNode tag. In case of any errors the application program should send back an error message.
The "Error" message might be sent by any component. It is composed of the following structure:
MESSHEADER "\Subject Error" "\MessageId " <Id of message that caused the error> "\ErrorSubject " <the type of error that occurred> "\ErrorMessage " <the actual error string>
The work on the OHP protocol has so far been largely a "paper-based" exercise. Two simple prototypes of the original protocol were built on top of the HOSS system and on top of Microcosm. However, the protocol has been much expanded in both size and functionality since these prototypes. The next push should be to produce working clients and servers so that outstanding issues may be resolved; and there are many.
An important purpose of investing this time and effort is to produce a protocol and tools that will be understood and hopefully adopted by the Web community as they move to link servers. However the current proposal makes no suggestions as to how such a transfer could be facilitated.
An important feature of open hypertext systems has been the ability to define and apply context for links (and indeed all other hypertext objects). A full implementation of the protocol must include fields for trafficking this information. At present this information is missing, as it was felt that we needed to consider the implications of how this context would be applied. Would context be "set" on the server by some message , and then be held until reset (implying that the server must hold this state) or would each message carry any context requirements (which might be quite large and imply further communication overheads).
The current version of the protocol makes a first stab at a definition of a Locspec. However, the web community is currently making an investment in this area (as well as in Pspecs) through the xml/xll working groups. Without agreement on how to treat the opaques within the current proposal, we will not be able to interoperate. There is much work that can be done in this area, and such work must ensure interoperability with emerging web standards.
At present the protocol assumes that the semantics of link traversal are that when a source endpoint is "activated", the link(s) to which it attached are followed and the client will be presented with the content of any nodes which contain destination endpoints. The model also allows that some script attached to the link might be activated. It is assumed that the client then handles display issues, for example, presenting the user with a selection list of destination documents and the task of paging the document to the correct point. However, there are a number of potentially separate processes implied in this model of traversal (from the Locspec, derive the dataRef; from the dataRef, derive the endpoint; from the endpoint, derive the links; from the link, derive the list of endpoints; from the endpoints, derive the dataRefs; from the dataRefs, derive the Nodes; from the nodes fetch the content). It might be necessary to break out these processes and to specify separate messages for each, and then perhaps to provide some messages which are composites of these.
The role of the CSF was discussed in section 3, and is an important issue. It is possible to view the client two ways. One can view the whole client side (CSF plus all client side applications) as one process. This is certainly the case from the point of view of the server, which need not be concerned with client side architectural issues. However, there are important client side architectural issues from the point of view of the application writer. If OHP aware applications are to be interchangeable they must be able to understand which services they must provide, and which they will get from the CSF or other applications. This issue re-enforces the need for a reference architecture; until we have defined the environment in which the protocol must exist, it will continue to be difficult to fully specify the protocol itself.
We believe that the next stage in the development of the protocol must involve some implementations which will can be used to experiment with resolutions to the outstanding issues.
This Appendix contains a proposal for location specifications, presentation specifications, content identifier specifications and script specifications.
The definition of the location specifications has been quite a controversial issue during the development of this proposal (see thread "opaque locspecs"). The two main camps being the "opaque" people on one side and the "HyTime" people on the other. The argument here, first suggested in Reich, 1997 towards opaque location specification is that for the link server location specifications should be opaque because the link server does not actually deal with them but rather wants to handle them as uninterpreted byte blocks. The HyTime (HyTime, 1992) followers on the other hand argue that at some point you actually have to have a specification so that an application is able to locate a specific position within a document's multimedia content. If you have to define it use an existing standard, in order to deal with location specifications in an abstract, platform independent way.
We have learned from both viewpoints and have concluded that both are right. Therefore, we do not treat location specifications as opaque, but we allow components to define their own location specifications, to be used instead of the definition given here, within OHP.
A number of additional criteria have influenced our decision for the current definition of location specifiers:
As an example let us take the simplest data type, e.g. ASCII text. Most systems have developed similar fairly rich methods of locating strings. The location specification should include standards for these methods. Later, we might extend standards for such things as pictures, formatted text, videos and streaming data. But opaque types will always be allowed and supported.
We also would like to stress the point that standardisation of location specifications is only partially subject to OHP. This can be compared to the situation with the document management protocol: strictly speaking this should not be part of the definition of OHP; however, if OHP should be really useful there have to be some common assumptions about both location specifications and document management functionality. For the current version of OHP we therefore provide these features so that OHP as a protocol can be implemented.
Now that we have explained in general our decisions we are able to define location specifications as part of OHP.
LOCSPEC = "\ContentType " <type, e.g., ASCII, binary> "\Content " <Mime encoded text string> "\LocVID " <LocVersionID> "\Loc " LOC "\EndLoc "
Location specifications consist of a content type, the content itself as well as the actual location data. LOC is defined as
Loc = { NAMELOC | DATALOC | TREELOC | PATHLOC | SCRIPTLOC | NALOC }
In the following subsections we will explain these different basic types of location specifications. Again, it is up to the developers to introduce their own additional location specifications or to add additional tags where necessary for specific applications. For most cases though, the proposed set of location specifications should be sufficient.
Name space locations are used to reference an object by its name. The definition of name locations is as follows:
NAMELOC = "\LocType NameLoc"
Data locations are co-ordinate locations, i.e., objects are addressed by their relative position to another object. Data locations will be heavily used by OHP as most systems define dataRefs by relative positioning, for instance by keeping an offset. In order to know how this dimension specification should be interpreted, i.e. to get its data type, a quantum tag is defined. CountList follows the HyTime semantics of defining a dimension list. In particular, two markers define beginning and end of a node on an axis thus resulting in (number of axes * 2) markers.
A reverse counter is kept in order to do cross checking of validity of datarefs. In case the expected object still can not be found an overrun behaviour can be specified: the error can simply be ignored, the markers can be truncated to the last unit on the axis, or an error can be raised.
The HyTime time quantum "utc" expects items in the form yyyy-mm-dd hh:mm:ss.decimal, e.g., 1997-09-24 17:07:22.6122.
DATALOC =
"\LocType DataLoc"
"\Quantum " { "string" | "int" | "byte" | "utc" }
"\CountList " <list of Strings being interpreted by the application
program>
"\RevCountList " <list of Strings being interpreted by the application>
"\Overrun " { "ignore" | "error" | "trunc" }
Tree locations can be used for addressing a single object within a tree. The addressing is done in a way that on each level of the tree an object is selected by its position. These position numbers are expressed in "\CountList". For example a count list of "1 2 3" applied to an object referencing a book would get the third section of the second chapter of the book (assuming that a book has a structure with chapters and sections).
TREELOC =
"\LocType TreeLoc"
"\Overrun " { "ignore" | "error" | "trunc" }
"\CountList " <list of numbers>
As opposed to tree locations path locations are used to address a range of nodes by a path. This is done by addressing a tree as though it were a matrix in which the rows are the levels of the tree and the columns are the paths. Therefore the count list of a path location consists of an even number of pairs: the first pair identifies the columns (i.e. the paths to the leaves) and the second pair selects the rows.
PATHLOC =
"\LocType PathLoc"
"\NodeId " <NodeId>
"\Overrun " { "ignore" | "error" | "trunc" }
"\CountList " <list of numbers>
OHP does not define a specific query mechanism for addressing locations (as does for instance HyTime with the standard DSSSL Query Language, SDQ). However, by allowing script locations we define a way for those hypertext systems that use scripts to identify and address locations at the client's side. Scripts are also treated as opaque to OHP and are dealt with in Appendix D : Script Specification.
SCRIPTLOC = "\LocType ScriptLoc" "\ScriptId <ScriptId>
An idea borrowed from HyTime is to address data that is currently not accessible. This could be a printed book which is not available on-line, a radio broadcast or even a person or an organisation. The point is that it might in some cases make sense to reference these nodes without having a application program for them. Instead, the application program could display a notification string, stating for example where to find a book in a shelf in a library. We call this location specification NALoc for "not accessible" location.
NALOC = "\LocType NALoc" "\Location " <string as description of the object and its physical location>
PSPECS may be used to store, and thus re-apply a required presentation for any hypertext object that a client may wish to display. A client might store a PSPEC as a byte stream, which would then later be retrieved and interpreted by the same client. We are aware that strictly speaking presentation styles should not be defined within OHP (Anderson, 1997). However, if we hope to achieve interchangeable client programs , then there must be some standard vocabulary for naming these presentation attributes. We are aware of efforts within the web community to define style sheets, and as these standards develop, we should evaluate them and adopt them as appropriate. For the present we propose that we adopt a syntax as follows:
PSPEC = "\Name " <a string> ["\Colour " <colour>] ["\Style " <style>] ["\Visibility " "true" | "false"]
Following the original proposal we suggest a triplet of colour, style, visibility, each of which is optional. The above definition allows us to only put these things if we have them, and we could also add other tags if needed. We will define some tag values which will be understood.
We assume that the eight primary computer colours are supported, i.e. black, blue, cyan, white, magenta, green, red and yellow.
As minimal subset of styles we define flashing, bold, italic, outlined and shaded.
Of course, this syntax may be extended by the addition of further name and value pairs. Much further work needs to be done on discovering the sort of attributes which people wish to store.
We recommend that the following definition for CONTENTSPEC be used, until such time as further work has improved on this.
CONTENTSPEC =
"\Name " <the content's name, typically a file name, a URL or a DMS handle>
"\Location " "FileSystem" | "Internet" | "DMS"
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
For example we might have
\ContentSpec
\Name N:\\DOCS\\FILE.TXT
\Location FileSystem
\Attributes
\Name owner \Value hcd
\EndAttributes
\EndContentSpec
or
\ContentSpec
\Name http://www.ecs.soton.ac.uk/~hcd/
\Location Internet
\EndContentSpec
As far as the link server is concerned the CONTENTSPEC information is opaque. It stores the string, and when the node is required it sends this back. The client side is expected to provide some component which will be able to interpret this string in the cases where the client is asked to display a document. Typically this will be the CSF, which will then organise to actually get the document from the file system or the Internet or the document management system that it is using (which may actually be the link server itself if the link server is a hyperbase).
We recommend that the following definition for SCRIPTSPEC be used.
SCRIPTSPEC =
"\Language " <name of the script language, e.g. JavaScript, etc.>
"\Data " <the actual script>
"\Attributes "
{"\Name " <the attribute's name>
"\Value " <its value>}*
"\EndAttributes "
This is a simple definition, but will allow scripting to be added to an application with little extra complication.
Please note that references to Internet resources are annoted with a date showing the day when these references where checked for their validity the last time.
Anderson, K.M. A Critique of the Open Hypermedia Protocol. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www.cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Davis, H., Lewis, A. & Rizk, A. OHP: A Draft Proposal for a Standard Open Hypermedia Protocol (Levels 0 and 1: Revision 1.2 - 13th March. 1996). 2nd Workshop on Open Hypermedia Systems, Washington, March 1996. Available as http://www.ecs.soton.ac.uk/~hcd/protweb.htm [1997 October 15].
Davis, H. Channels in OHP. Thread in OHS Mailing List (1997 June 6) Available as http://www.csdl.tamu.edu/ohs/archives/0032.html [1997 October 15].
Goose, S., Lewis, A. & Davis, H. OHRA: Towards an Open Hypermedia Reference Architecture and a Migration Path for Existing Systems. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www .cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Grønbæk, K. & Trigg, R.H. Toward a Dexter-based model for open hypermedia: Unifying embedded references and link objects. In: The Proceedings of Hypertext '96. ACM 1996. Available as http://www.cs.unc.edu/~barman/HT96/P71/Groenbaek-Trigg.html [1997 October 15].
Grønbæk, K. & Wiil, U.K. Towards a Reference Architecture for Open Hypermedia. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www.cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Halasz, F. & Mayer, S. (edited by Grønbæk, K. & Trigg, R.H). The Dexter Hypertext Reference Model. Communications of the ACM. pp 30-39. 37(2). Feb. 1994.
ISO - International Organization for Standardization: Information Technology - Hypermedia/Time-based Structuring Language (HyTime), ISO/IEC 10744, 1992.
Marshall, C. C., Shipman, III, F. M. & Coombs, J. H.VIKI: Spatial Hypertext Supporting Emergent Structure, Proceedings of the 1994 European Conference on Hypertext, ACM, 1994.
Nürnberg, P. opaque locspecs. Thread in OHS Mailing List (1997 April 17). Available as http://www.csdl.tamu.edu/ohs/archives/0023.html [1997 October 15].
Open Document Management API (ODMA) Open Document Management API Version 1.5. Available as http://www.aiim.org/odma/odma15.htm [1997 October 15].
Pam, A. Fine-Grained Transclusion in
the Hypertext Markup Language. Available as
http://xanadu.com.au/xanadu/draft-pam-html-fine-trans-00.txt;
[1997 October 15].
Reich, S. How OHP's LocSpecs could benefit from ISO/IEC 10744. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www.cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].
Wiil, U.K. & Leggett, J. The HyperDisco Approach to Open Hypermedia Systems. In: The Proceedings of the ACM Conference on Hypertext '96, Washington D.C., pp. 140-148. ACM Press. March 1996. Available as http://www.cs.unc.edu/~barman/HT96/P11/HyperDisco.ps.gz [1997 October 15].
Wiil, U. K., and Østerbye, K. (eds.). Proceedings of the ECHT '94 Workshop on Open Hypermedia Systems, (Edinburgh, Scotland, September 1994). Department of Computer Science, Technical Report R-94-2038, Aalborg University. October 1994. http://www.daimi.aau.dk/~kock/OHS-ECHT94/
Wiil, U.K. & Whitehead, J.E. Interoperability and Open Hypermedia Systems. Proceedings of the 3rd Workshop on Open Hypermedia Systems, Southampton, April 1997. CIT Scientific Report no. SR-97-01, The Danish National Centre for IT Research. Available as http://www.cit.dk/publikationer/download/citrap_sr9701.pdf [1997 October 15].