The Search Engine Optimisation (SEO) team have been looking into how orphan pages impact the search engine performance of the University’s website. Orphaned pages are pages that are not linked to from any other section of our site, and can include campaign landing pages, old blog content or archived information.
If there is a large quantity of pages that are orphaned, either intentionally or not, this will be diminishing the search performance potential for that content. The idea is to identify and explore those pages that have untapped potential, and either re-link them to the website structure, or remove them entirely to reduce the continued risk of index bloat and crawl waste. The main goal for SEO is to drive and improve search engine visibility for relevant searches, and we recognise that having a vast number of pages unlinked to any aspect of our website is negatively affecting the domain performance.
Search engines may still decide to index orphaned pages, this can be a result of other websites linking to it or if we have submitted it to search engines ourselves, but search engines still deem those not linked pages as less important than other pages that are internally linked.
How do we find orphaned pages?
Finding orphan pages is key to solving our problems. From our crawl reports and analysis, we have realised that a sizable proportion of our content is classified as orphaned, some of which is indexed.
There were a number of revealing results from our audit including:
- a large number of 404 pages and old redirected pages in sitemaps.
- news, events, seminar pages dating back to 10 years ago.
- many pages were purposely taken out of the navigation (content owners using this as a way of archiving their site or hiding pages) without deleting the page itself.
- some old landing pages which could also be removed.
The majority of those pages which are unlinked can be classified as expired content, these pages are considerably contributing to our index bloat problem. A total of 36,000 unique unlinked urls (that are indexed in search results). The majority exist under old news articles in the directory /news/ and then a large number of instances under the schools (faculties) information architecture. Reflecting on our results from the crawl analysis, it was evident that we need to reduce these sections and proactively focus on outcomes to enhance performance.
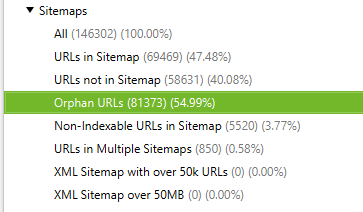
Figure 1: detective work looking and finding orphan pages
It’s clean up time!
If you love crawl visualisations like we do at the University of Southampton you will notice that orphan pages will show up here which definitely provides perspective as well as creating an unusual piece of artwork to display at your workspace!
More seriously, how can we as SEO specialists prevent orphan pages from diluting our website’s performance, but also adding to a lot of digital waste. Firstly we need to understand what impact this has on key performance metrics. For example:
- orphan pages have a low ranking capability
- organic traffic is typically low
- index bloat and crawl waste
- content dead-ends and poor user experience
- occupying valuable bandwidth, storage without driving traffic or conversions
- overall affecting domain score
- environmental burden to our digital estate.
In reality it may be a difficult task for any large website to have zero orphan pages. However, what matters is that we focus on creating a framework of structuring content in a user-centric way and aim towards a stronger internal linking structure. Orphan pages should be a minimal exception that proves the rule, rather than being treated as standard practice.
Maximise our efforts
Crawl waste is very common across large domains that contain out of date or obsolete content that is not updated or removed. Leading to hundreds or even thousands of pages that do not need to exist, weighing the website down. Crawl waste exists where bots regularly crawl pages or broken links that they shouldn’t have to. That is why it is so important to address expired content, and have pages and links return an indexable status or at least a 301 redirect. We are already making gains with this kind of investment in web maintenance, this will really pay us dividends in the long term.

Caption: we keep looking for index bloat and orphan pages
Reduce our bloat
Continuing to hoard orphan pages that are tricky to find signals to search engines that a large portion of our content is not relevant enough to warrant ranking. The good news is it is simple enough to fix and we are already working hard on that front! Removal of low quality pages provides a better chance for more important pages to improve their search visibility in Google. We strongly believe having a plan for when to retire content is one of the most important parts of a content strategy.
Next steps for the University website
It is imperative for the future of the website that we provide users and search engine crawlers the best possible chance to discover our most important web pages. Removing expired content is another step forward in optimising our crawl budget, relieving some of that index bloat, and getting closer to improving overall user experience.
That’s not the end of it though. As part of OneWeb there was a strong focus on collaboration with the wider University and digital stakeholders. So if you hear from us with regards to minimising orphan pages, please help us to achieve some of our intended outcomes:
- identify large content areas for removal, such as news, events, seminars.
- clear up the domain by identifying errors in our sitemaps or pages resulting in a 404 due to being deleted.
- identify if there are any high value content areas that are at risk.
We are working on a proposal on how to retire this vast amount of content, and will share more with you as we progress. In the meantime, we would like to invite you to share any ideas.
You can contact the SEO Digital User Experience team by emailing us:
Kath Sellwood: kath.sellwood@soton.ac.uk
Rayne Prendergast: r.e.prendergast@soton.ac.uk
Elise Corbin: e.corbin@soton.ac.uk